It’s this time of the year… when heads of state address their nations with messages of hope and reflect on the past year and the challenges ahead. I was looking for a data set to do some text analysis and I thought this could be an interesting one. I collected a few Christmas messages from some of Europe’s heads of state (to be more precise, the English translations available).
Here’s the set that I’ll use:
Processing the source data and loading it into Neo4j
I’ve used this python script to process the text in the documents. It uses NLTK to exclude punctuation elements and stopwords in order to produce a clean list of tokens…
cleantext = ''.join([c for c in text if c not in non_words]).lower() tokens = [tk for tk in word_tokenize(cleantext) if tk not in stopwords]
… from the tokens I get the stems again using NLTK:
stemmer.stem(tk)
The resulting structure contains word stems, their frequency and the words that share the same stem. Here’s a fragment of the clean data ready to be imported into Neo4j:
[
{'stem': 'presid', 'count': 1, 'words': ['president']},
{'stem': 'ireland', 'count': 4, 'words': ['ireland']},
...
]
This is passed as the $list parameter to a cypher script that populates the Neo4j graph:
CREATE (sp:Speech { country: $country}) WITH sp
UNWIND $list as entry MERGE (st:Stem { id: entry.stem})
MERGE (st)-[:USED_IN { freq: entry.count }]->(sp)
WITH st, entry.words as words UNWIND words AS word
MERGE (w:Word { id: word })
MERGE (w)-[:HAS_STEM]->(st)
RETURN COUNT( DISTINCT st) AS stemCount
The model in Neo4j is pretty simple. It contains three types of entities:
- Speech nodes representing the message by a head of state
- Stem nodes representing a word stem. They are connected through the USED_IN relationship to the Speech nodes where they are used. The relationship has a property called freq indicating the number of times the word stem is used in a particular speech.
- Word nodes representing the actual words that were used in a speech. Words are linked to their stem through the HAS_STEM relationship.
Here is an excerpt of the graph showing the stem ‘challeng’ shared by the words ‘challenge’ and ‘challenges’ and used in the messages by the heads of state of Spain, Ireland, Sweden and the UK.
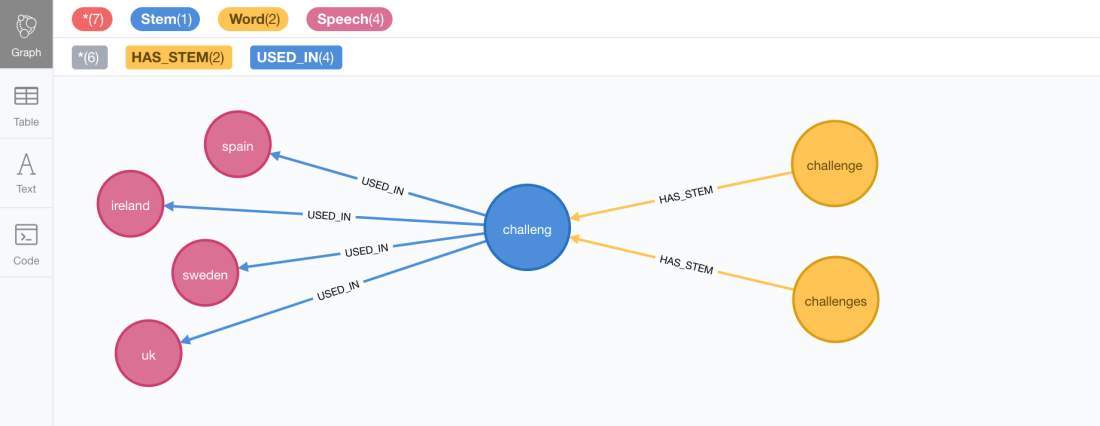
It is worth mentioning that I’ve made an arguable modelling decision which is to link the stems to the speeches and aggregate all the words that share the same stem around the stem node, losing the link between the word and the speech where it was used. This simplifies the model for the type of analysis that we’ll run in this QuickGraph but could be an issue if we wanted to know which exact words (not just the stem) were used in a particular speech.
Querying the graph
Let’s now run some queries on this dataset.
Which words appear in all Christmas messages?
Some words like ‘Christmas’ or ‘peace’ appear in all messages. Here’s how we can get the whole list of word stems used in all speeches and all word variants of each stem.
MATCH (s:Speech) WITH count(s) AS countryCount MATCH (w:Word)-[:HAS_STEM]->(st:Stem)-[:USED_IN]->(speech) WHERE size((st)-[:USED_IN]->()) = countryCount RETURN st.id AS stem, collect(distinct w.id) AS words

If instead of absolute word frequency we look at the count of speeches where the word appears, we can get the list of most common words. And this is something that would look great in a tag cloud. Here is the cypher query that returns the top 30, followed by a beautiful heart-shaped tag cloud using that data (courtesy of WordClouds).
MATCH (st:Stem) RETURN st.id AS stem, size((st)-[:USED_IN]->()) as freq ORDER BY freq DESC LIMIT 30

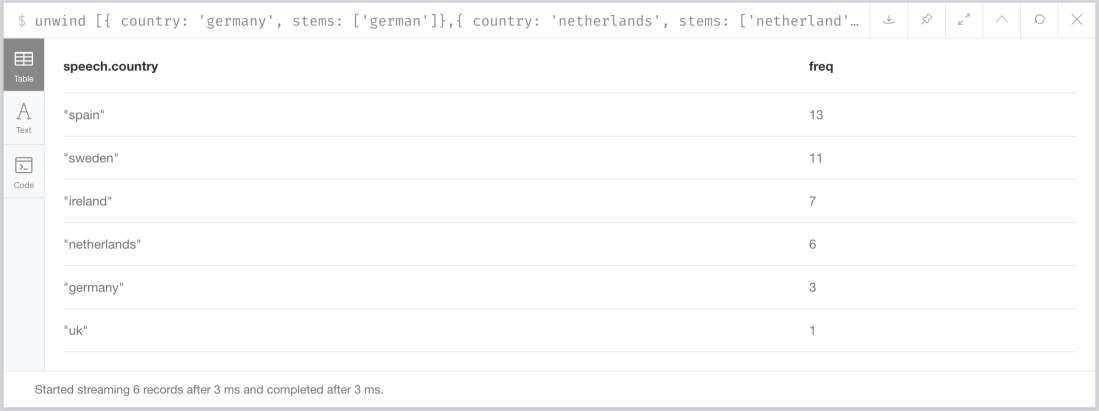
How many times is the country’s name or demonym mentioned in a message?
All heads of state mention their country’s name (or the country’s demonym) in their speeches. Some more than others. Here’s the cypher query that reveals who does it more and who does it less:
UNWIND [{ country: 'germany', stems: ['german']},{ country: 'netherlands', stems: ['netherland','dutch']},{ country: 'sweden', stems: ['swed']},{ country: 'ireland', stems: ['ireland','irish']},{ country: 'spain', stems: ['spa']},{ country: 'uk', stems: ['brit']}] as item
MATCH (st:Stem)-[ui:USED_IN]->(speech:Speech { country: item.country})
WHERE any(word in item.stems where st.id contains word)
RETURN speech.country, sum(ui.freq) as freq ORDER BY freq DESC
producing the following results:
Word frequencies
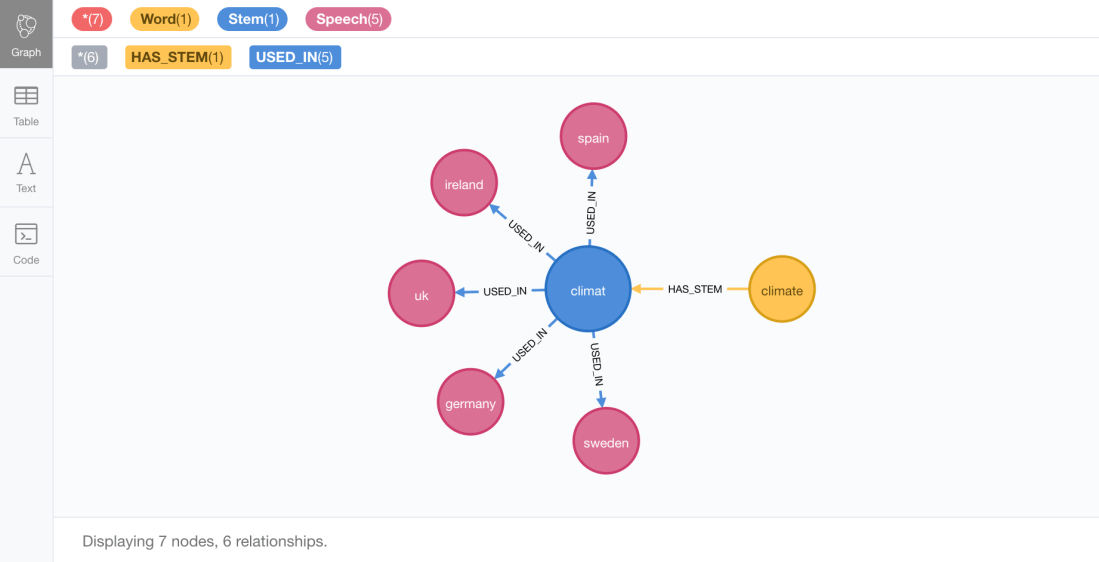
We can get the set of speeches where a word is used using the following graph pattern
match path = (:Word { id: "climate"})-[:HAS_STEM]->(st:Stem)-[ui:USED_IN]->(s:Speech)
return path
which returns this subgraph:
A simple variant of the previous query can give us the frequency of a specific word stem by speech. Here’s what the cypher looks like:
match (:Word { id: "climate"})-[:HAS_STEM]->(st:Stem) with st
match (s:Speech) with s, st
optional match (st)-[ui:USED_IN]-(s)
return s.country as country, coalesce(ui.freq,0) as freq

And the result is bar chart material

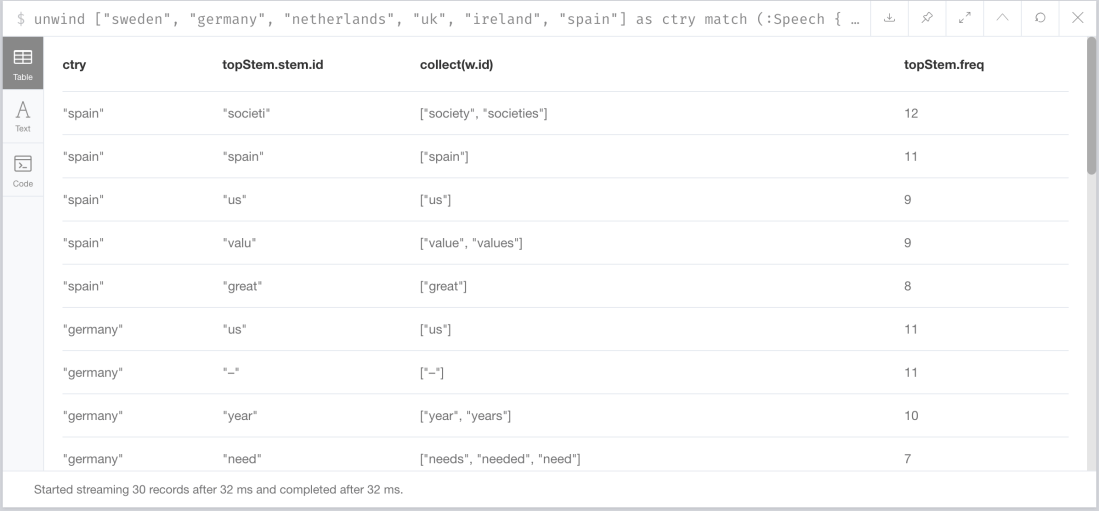
Which are the top five words in each speech?
It’s sometimes interesting to look at the stems that are repeated the most in a message as they sometimes show a bit of the spirit of the message. The following cypher query returns the top 5 stems (and words) for each message:
unwind ["sweden", "germany", "netherlands", "uk", "ireland", "spain"] as ctry
match (:Speech { country : ctry })<-[ui:USED_IN]-(st:Stem)
with ctry, ui.freq as freq , st order by freq desc
with ctry, collect({freq:freq, stem: st}) as stems
unwind stems[0..5] as topStem
match (x)<-[:HAS_STEM]-(w:Word) where x = topStem.stem
return ctry, topStem.stem.id, collect(w.id), topStem.freq
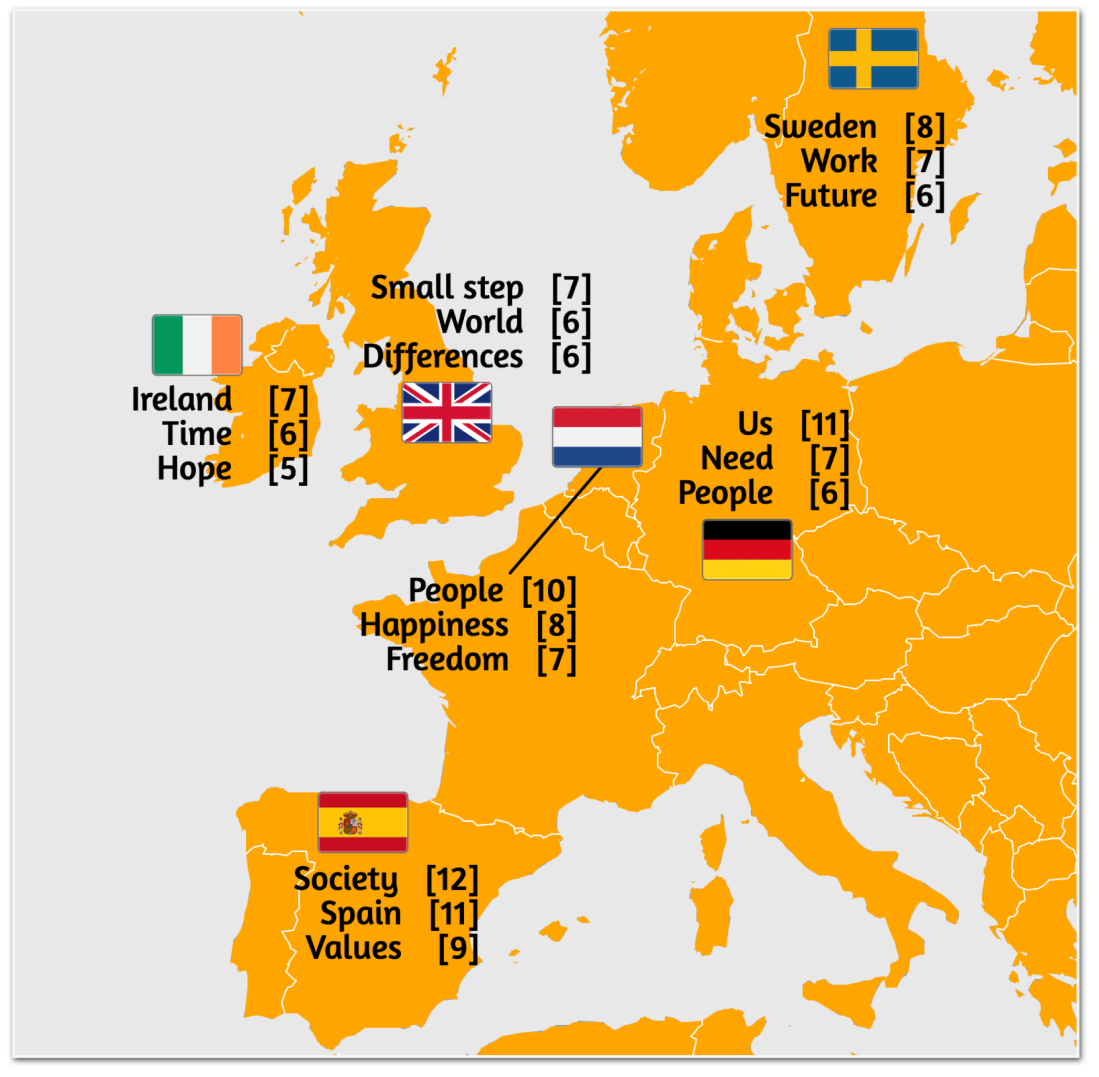
Producing the following results:
Let’s see how they look on a map (courtesy of StepMap)
Graph Algorithms
And to conclude, I’ll show how to use the overlap similarity algorithm to find which are the most similar speeches based on the overlap of word stems.
To remove some noise, I’ll use all stems with a frequency higher than 3 and return results producing an overlap similarity over 40%. Here’s how we can do it with four lines of cypher:
match (st:Stem)-[ui:USED_IN]->(s:Speech) where ui.freq > 3
with { item: id(s), categories: collect(distinct id(st))} as dt with collect(dt) as data
call algo.similarity.overlap.stream(data) yield item1, count1, item2, count2, intersection, similarity where similarity >= 0.4
return algo.asNode(item1).country, count1, algo.asNode(item2).country , count2, intersection, similarity order by similarity desc
This returns a nearly 70% similarity between the speech given by the Spain and UK heads of state… the interested reader can interpret these results 🙂

Ok, that’s it for QG#11. My plan is to extend this analysis using more advanced features in NLTK like identifying parts of speech or named entities, combining it with WordNet or domain ontologies… but this will be the next decade.
Enjoy playing with the code (in GitHub as always), analyse other datasets and share your experience.
Happy New Year everyone!
