The UNESCO Thesaurus is a controlled and structured list of terms in the areas of education, culture, natural sciences, social and human sciences, communication and information. It’s used used to annotate documents and publications like the ones in the UNESDOC digital library.
The Thesaurus is available as a multilingual SKOS concept scheme and at the time of writing, the available languages were English, Spanish, French, Russian and Arabic (download link).
SKOS (Simple Knowledge Organization System) is an RDF based model for expressing the basic structure and content of concept schemes such as thesauri, taxonomies and other types of controlled vocabulary. Learn more about it here.
Loading the UNESCO Thesaurus into Neo4j
Neosemantics (n10s) includes methods to import SKOS concept schemes into Neo4j in a fully automated way. Here’s what the process looks like
Monolingual Thesaurus
Let’s say we want to load the Thesaurus in French only (replace French with your preferred language here).
Step 1: Setting the Graph Config
call n10s.graphconfig.init({ handleVocabUris: "IGNORE",
handleMultival: "ARRAY",
multivalPropList: ["http://www.w3.org/2004/02/skos/core#altLabel"] })With handleVocabUris: "IGNORE" we are asking n10s to ignore the namespaces used by SKOS and keep only the local names. We will see when we import the Thesaurus into Neo4j that nodes representing categories will have properties called altLabel or prefLabel instead of the fully qualified skos:altLabel or skos:prefLabel. With handleMultival: "ARRAY" we are setting n10s to import multivalued properties into arrays in Neo4j. By using multivalPropList we can specify the list of properties we want this behaviour to be applied (the rest will be stored as atomic values). In this case we expect concepts in the Thesaurus to have one single preferred label (prefLabel) and potentially multiple alternative labels (altLabel).
Step 2: Importing the Turtle serialisation of the Thesaurus directly from the UNESCO site.
call n10s.skos.import.fetch("http://vocabularies.unesco.org/browser/rest/v1/thesaurus/data?format=text/turtle",
"Turtle", { languageFilter: "fr" })With this procedure we are importing the Thesaurus directly from its public address in vocabularies.unesco.org. With param languageFilter we indicate that we want to filter literal triples and only keep the ones tagged as French ("fr"). It should not take more than a second or two to process the 90K triples in the current version of the Thesaurus.
The imported graph reflects the information in Thesaurus as we can see in the next capture for a specific concept Health Services (“Service de santé”):

The information about a specific concept and the ones related to it can be retrieved with this simple Cypher query:
MATCH p = (:Class { prefLabel : "Service de santé"})<--()
RETURN pMultilingual Thesaurus
Alternatively, we may want to load the Thesaurus and include all available languages for concepts and terms. The approach is identical and only requires a small change to the Graph Config. (I’ll assume that we’ll empty the graph and start again here).
Step 1: Setting the Graph Config
call n10s.graphconfig.init({ handleVocabUris: "IGNORE", handleMultival: "ARRAY", keepLangTag: true })In this case we want both preferred and alternative labels to be stored in arrays because we expect to have several of them (at least one per language), that’s why we don’t need to specify the multivalPropList as we did before because all will be stored in arrays. There is also a new param set (keepLangTag) to indicate that we want to keep the language tag with each value.
Step 2: Importing the Turtle serialisation of the Thesaurus directly from the UNESCO site.
call n10s.skos.import.fetch("http://vocabularies.unesco.org/browser/rest/v1/thesaurus/data?format=text/turtle")Identical to the previous one but this time without the filter on French literals. We are keeping all languages now.
The resulting graph is much richer now, and for every concept we have a nice set of multivalued properties. Let’s see what the Health Services concept looks like now:
MATCH (c:Class {
uri: "http://vocabularies.unesco.org/thesaurus/concept412"})
RETURN c.prefLabel as preferredLabels, c.altLabel as alternativeLabels
This time we are looking up by URI (:concept412). Remember that URIs are globally unique identifiers for concepts in a vocabulary. A primary key for lookup in a DB so to speak.
We can also do searches in different languages, and similarly produce the result in the same language. Here’s an example of a simple lookup using the Arabic version of the Thesaurus.
MATCH (c:Class) WHERE "خدمات صحية@ar" IN c.prefLabel
RETURN [x IN c.prefLabel WHERE n10s.rdf.hasLangTag("ar",x)| n10s.rdf.getValue(x)] AS prefLabel,
[x IN c.altLabel WHERE n10s.rdf.hasLangTag("ar",x) | n10s.rdf.getValue(x)] AS altLabelWhich would produce the following result:

Or the same concept this time in russian (lookup by URI again):
MATCH (c:Class { uri: "http://vocabularies.unesco.org/thesaurus/concept412"})
RETURN [x IN c.prefLabel WHERE n10s.rdf.hasLangTag("ru",x)| n10s.rdf.getValue(x)] AS prefLabel,
[x IN c.altLabel WHERE n10s.rdf.hasLangTag("ru",x) | n10s.rdf.getValue(x)] AS altLabel
Producing rich output with Cypher
The following Cypher query makes extensive use of comprehensions and aggregations to build a rich JSON structure for a given Thesaurus concept.
The query takes two parameters
- the identifier of the concept (its URI in this case)
- a list of languages
And returns the list of parent concepts in the Thesaurus with their ids, preferred and alternative labels. And it does it n times, one for each language in the list passed as param. Here is the Cypher in question:
MATCH taxonomy = (c:Class { uri: $uri})-[:SCO*]->(top)
WHERE NOT (top)-[:SCO]->() WITH taxonomy
UNWIND $langs as lang
RETURN collect({ lang: lang, taxonomy: [concept in nodes(taxonomy)| { pref: n10s.rdf.getLangValue(lang, concept.prefLabel), alt: [alt in concept.altLabel where n10s.rdf.hasLangTag(lang, alt) | n10s.rdf.getLangValue(lang, alt) ] }]}) as multilangNotice how we are using the n10s.rdf.getLangValue function to get the value of a property in the required lang and the n10s.rdf.hasLangTag to check whether a property value has a particular lang tag.
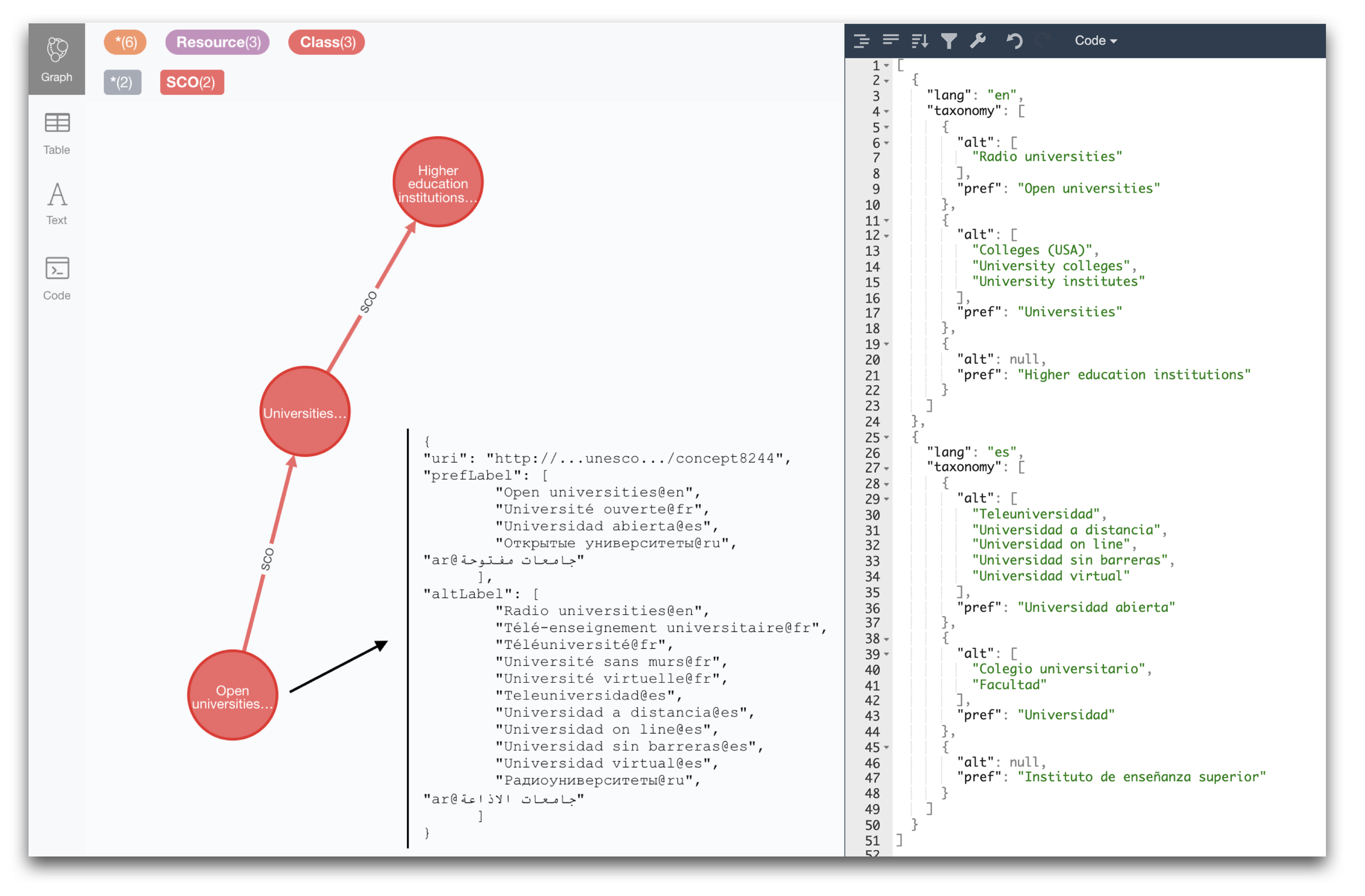
We can test the query on the concept “Open Universities” (uri: concept8244) in English and Spanish. All we need to do is set the properties using :param if we are running this in the Neo4j browser. Here’s how:
:param uri => "http://vocabularies.unesco.org/thesaurus/concept8244"
:param langs => ["en","es"]When we run the query above we get a single result serialised in JSON like the one to the right (courtesy of JSON Formatter). To the left we can see the actual structure in the graph that we are serialising.
Analytics on the Thesaurus Concepts
Just to finish the post I thought I’d add a little section on analytics. Once your thesaurus is stored in Neo4j, you can leverage the GDS library to run graph analytics on your data. Here’s how you can determine the centrality of the Concepts in your graph with two lines of code.
First we create a graph projection where we use the Class nodes and the RELATED relationships (feel free to change that and include also the SCO or even customise it by defining a Cypher-based projection. We will call our projection ‘thesaurus-analytics’.
CALL gds.graph.create('thesaurus-analytics', ['Class'], ['RELATED'])We can now run graph algos in the projected graph. I’ll select a couple of centrality ones in the alpha tier (experimental): articleRank and eigenvector centrality. Running them is pretty straightforward. I this example I’m streaming the results rather than persisting them in the graph.
call gds.alpha.articleRank.stream('thesaurus-analytics') YIELD nodeId, score RETURN n10s.rdf.getLangValue('en',gds.util.asNode(nodeId).prefLabel) AS concept, score ORDER BY score DESC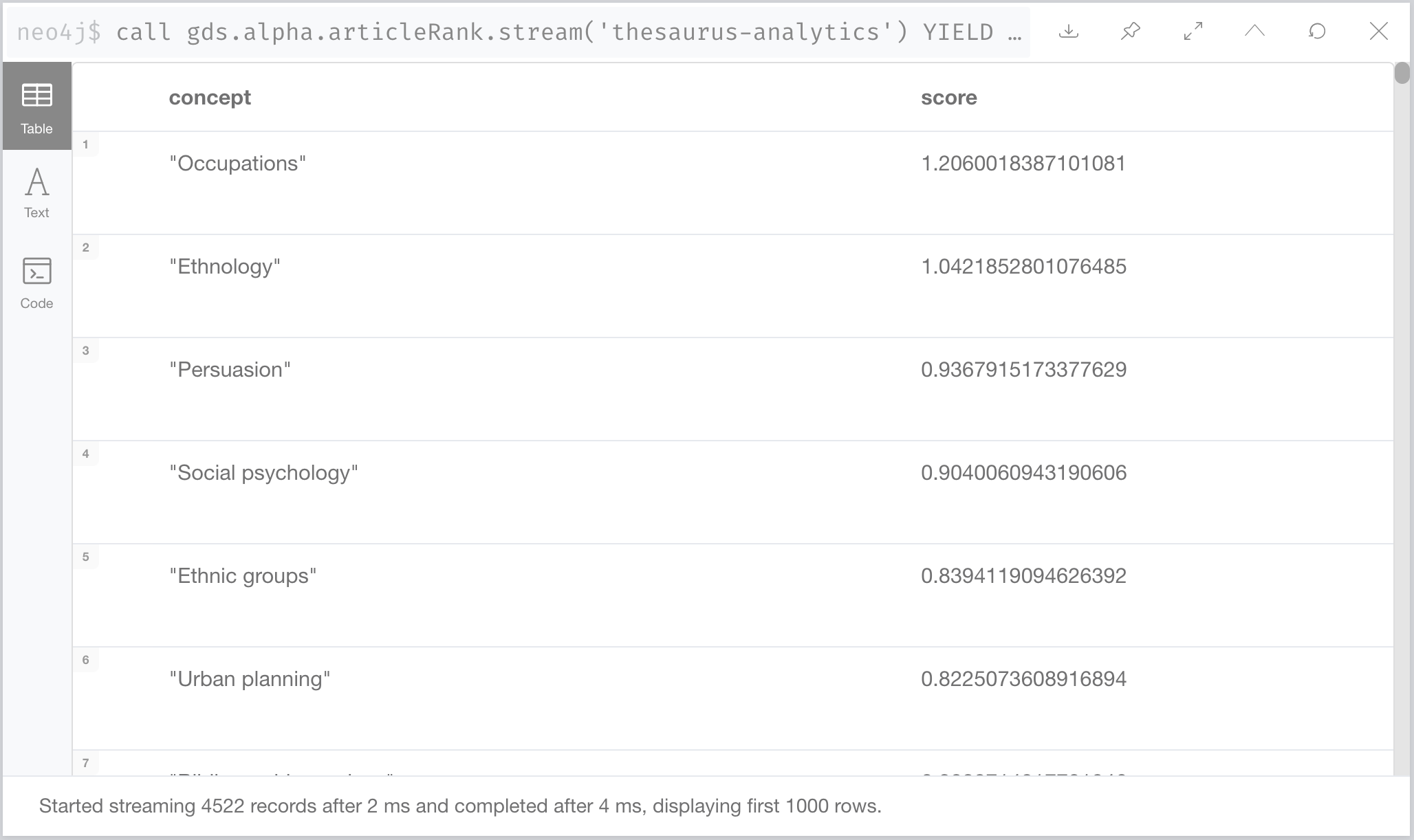
From the documentation, ArticleRank is a variant of the Page Rank algorithm, which measures the transitive influence or connectivity of nodes. Where ArticleRank differs to Page Rank is that Page Rank assumes that relationships from nodes that have a low out-degree are more important than relationships from nodes with a higher out-degree. ArticleRank weakens this assumption.
The same analysis, this time using eigenvector centrality:
call gds.alpha.eigenvector.stream('thesaurus-analytics') YIELD nodeId, score RETURN n10s.rdf.getLangValue('en',gds.util.asNode(nodeId).prefLabel) AS concept, score ORDER BY score DESC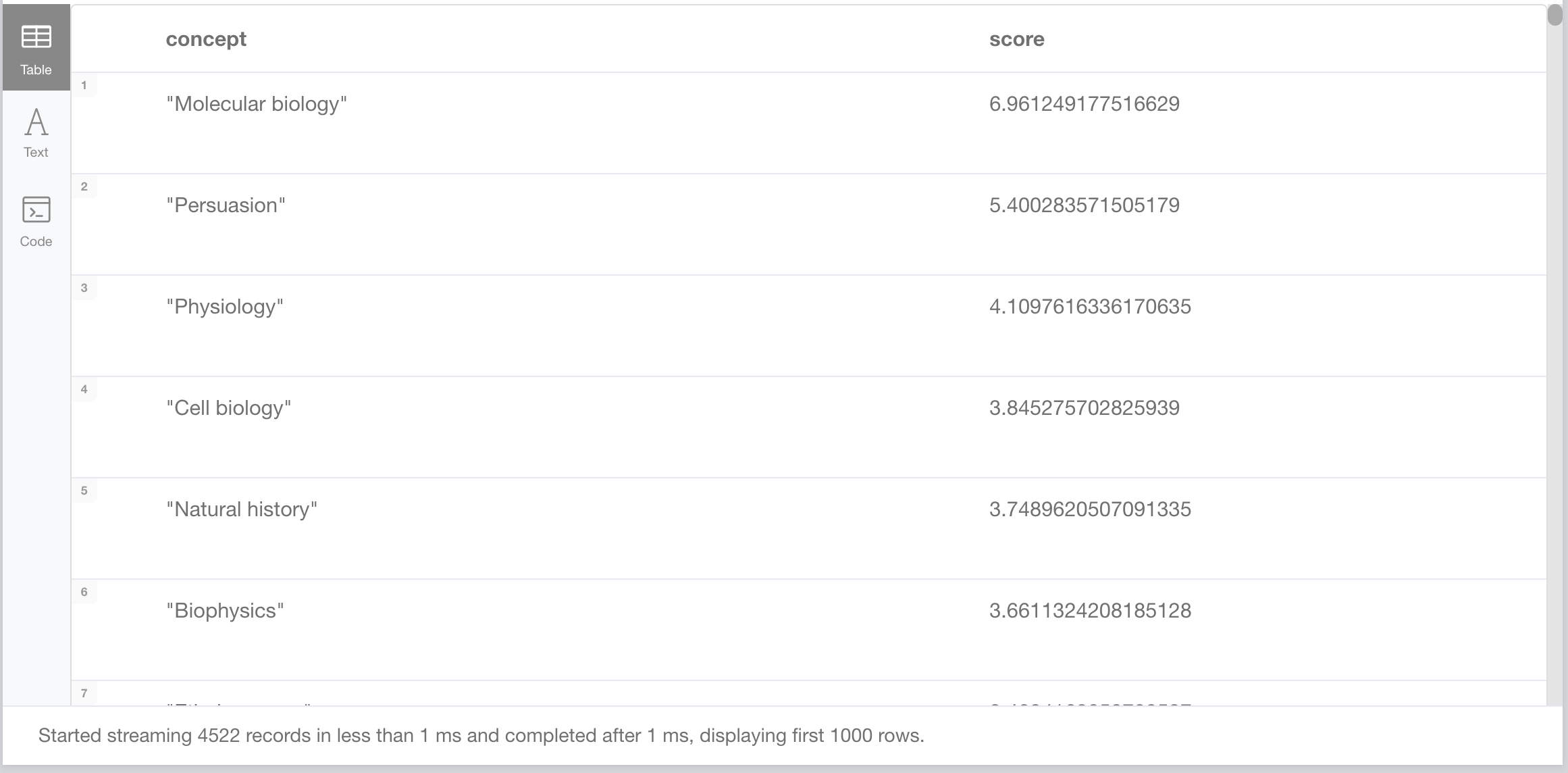
From the documentation, relationships to high-scoring nodes contribute more to the score of a node than connections to low-scoring nodes. A high score means that a node is connected to other nodes that have high scores.
Interestingly, very little overlap in the top results for one and other algos, but this is a topic for another post 🙂
What’s interesting about this QuickGraph?
I think here, it’s clearly how n10s helps in the handling of multilingual taxonomies, but equaly interesting is the ease of import (and export) from/to standards like SKOS. More interesting stuff on this thesaurus, involving unstructured data to come in next posts.
As usual, give it a try and give us your feedback! See you at the neo4j community site.

One thought on “QuickGraph#12 Working with a Multilingual Thesaurus”