The Objective
Say we have a dataset of multi-tagged items: books with multiple genres, articles with multiple topics, products with multiple categories… We want to organise logically these tags -the genres, the topics, the categories…- in a descriptive but also actionable way. A typical organisation will be hierarchical, like a taxonomy.
But rather than building it manually, we are going to learn it from the data in an automated way. This means that the quality of the results will totally depend on the quality and distribution of the tagging in your data, so sometimes we’ll produce a rich taxonomy but sometimes the data will only yield a set of rules describing how tags relate to each other.
Finally, we’ll want to show how this taxonomy can be used and I’ll do it with an example on content recommendation / enhanced search.
The dataset
We’ll use data from Goodreads on books and how they’ve been categorised by readers. In Goodreads, there is a notion of “shelf” which is a user created public category or tag that can be added to books and reused by other readers. Here is a page from Goodreads on a book along with the graph view of the data that we’ll extract from the page for this experiment.


Each book has a few shelves (genres) and an author, although I will not use the author information in this case.
Here is the data load script that you can try on your local Neo4j instance:
CREATE INDEX ON :Author(name)
CREATE INDEX ON :Book(id)
CREATE INDEX ON :Genre(name)
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/jbarrasa/datasets/master/goodreads/booklist.csv" AS row
MERGE (b:Book { id : row.itemUrl})
SET b.description = row.description, b.title = row.itemTitle
WITH b, row
UNWIND split(row.genres,';') AS genre
MERGE (g:Genre { name: substring(genre,8)})
MERGE (b)-[:HAS_GENRE]->(g)
WITH b, row
UNWIND split(row.author,';') AS author
MERGE (a:Author { name: author})
MERGE (b)-[:HAS_AUTHOR]->(a)
The data model is pretty simple as we’ve seen, and it only models three types of entities, the books, their authors and the genres. Here is the db.schema:

And some metrics on the tagging:
- AVG number of genres per book: 5.4
- MAX number of genres per book: 10
- MIN number of genres per book: 1
You can get them by running this query:
MATCH (n:Book) WITH id(n) AS bookid, size((n)-[:HAS_GENRE]->()) AS genreCount RETURN AVG(genreCount) AS avgNumGenres, MAX(genreCount) AS maxNumGenres, MIN(genreCount) AS minNumGenres
The Taxonomy Learning Algorithm
The algorithm is based on tag co-occurrence. The items in our dataset have multiple tags each, which means that tags will co-occur (will appear together) in a number of items. This algorithm will analyse the sets of items where tags co-occur and apply some pretty straightforward logic: If every item tagged as A is also tagged as B, we can derive that A implies B or in other words, the category defined by tag A is “narrower-than” the category defined by tag B. Easy, right?
Let’s look at the algo step by set using the simple model described before on books and genres. Books are our tagged items and the genres are the tags.
(b:Book)-[:HAS_GENRE]->(g:Genre)
STEP1: Compute co-occurrence
Co-occurrence is the basic building block for the algorithm and is in itself a quite useful relationship because it indicates some degree of overlap between tags and therefore a certain degree of similarity which is something that can be exploited for query expansion or recommendation.
The co-occurrence index between two categories A and B is computed as the portion of items in category A that are also in category B, this is a simple division of the number of items tagged as both A and B divided by the number of items in tagged as A.
COOC(A,B) = #items tagged as both A and B / #items tagged as A
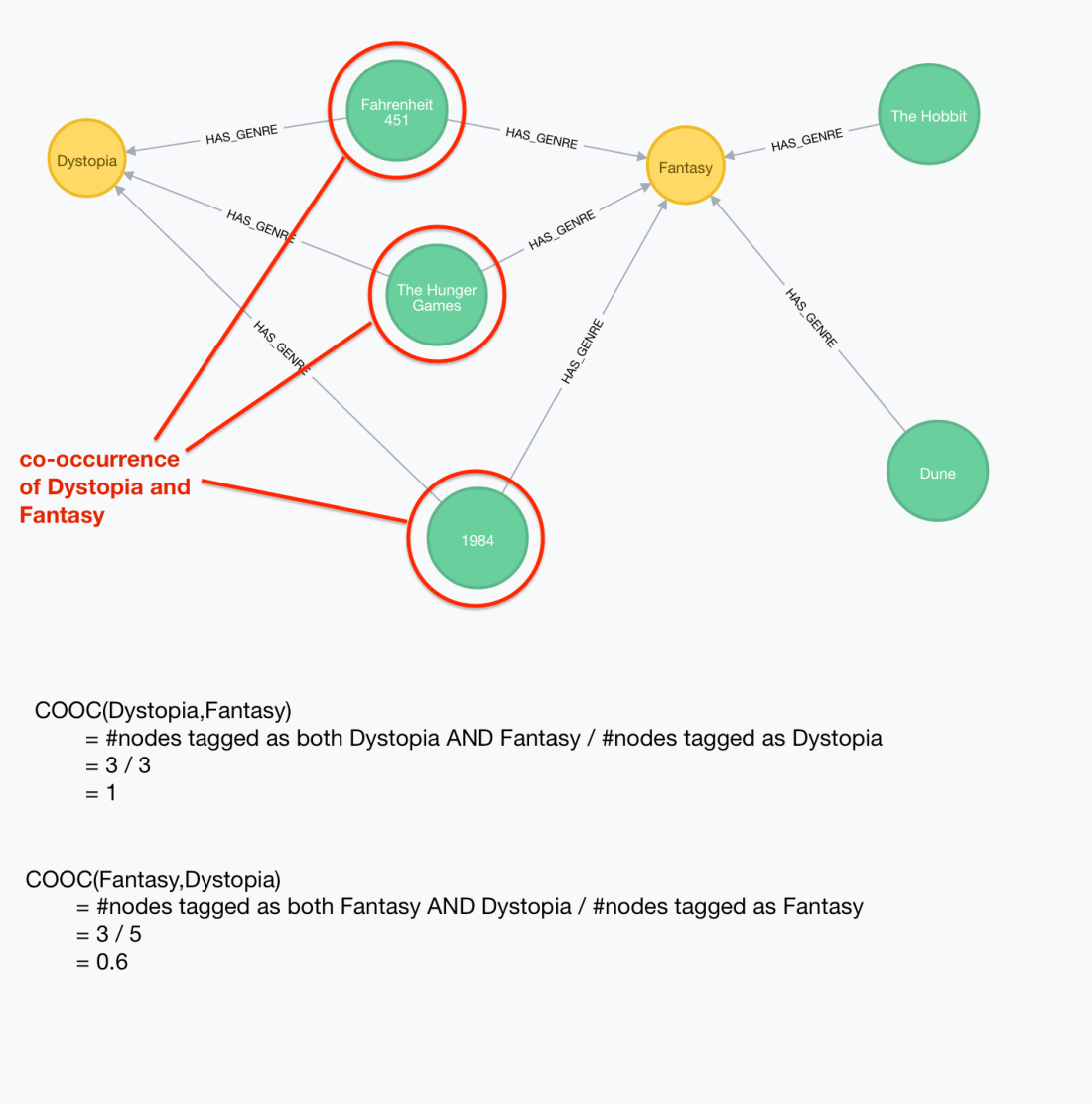
Notice that while the co-occurrence relationship is not directional, the co-occurrence index is so we will persist in our graph the cooccurrence of two tags as two relationships one on each direction containing the co-occurrence index.
In cypher:
MATCH (g:Genre) WHERE SIZE((g)<-[:HAS_GENRE]-()) > 5 //Threshold
WITH g, size((g)<-[:HAS_GENRE]-()) as totalCount
MATCH (g)<-[:HAS_GENRE]-(book)-[:HAS_GENRE]->(relatedGenre)
WITH g, relatedGenre, toFloat(count(book)) / totalCount AS coocIndex
CREATE (g)-[:CO_OCCURS {index: coocIndex }]->(relatedGenre)
I’ve also included in the Cypher implementation a WHERE clause (marked red) to exclude categories that contain fewer items than a given threshold. This is an optional adjustment that you may want to apply and like this one there are a number of optimisations that can be applied to the basic co-occurrence computation to make it produce higher quality results.
STEP2: Infer same-as relationships
Once we have co-occurrence in the graph, we want to detect equivalent genres. Two genres are equivalent if the co-occurrence index in both directions is 1 or in other words, if every item having genre g1 has also genre g2 and vice versa.
Here is the Cypher that does the job. Equivalent categories (genres) are linked through the SAME_AS relationship
MATCH (g1)-[co1:CO_OCCURS {index : 1}]->(g2),
(g2)-[co2:CO_OCCURS { index: 1}]->(g1)
WHERE ID(g1) > ID(g2)
MERGE (g1)-[:SAME_AS]-(g2)
STEP3: Infer narrower-than relationships
Here is where we infer the hierarchical relationship between two categories (genres). Very similar to the previous rule, we check now if one of the co-occurrence indexes is 1 and the other is less than 1. Or in English, if every item having genre g1 has also genre g2 but the opposite is not true.
The Cypher that creates the NARROWER_THAN hierarchy is as follows.
MATCH (g1)-[:CO_OCCURS {index : 1}]->(g2),
(g2)-[co2:CO_OCCURS]->(g1)
WHERE co2.index < 1
MERGE (g1)-[:NARROWER_THAN]->(g2)
STEP4: Reduce transitive narrower-than relationships
Finally, this computation may have produced more NARROWER_THAN relationships than needed so we want to remove transitive ones. If (X)-[:NARROWER_THAN]->(Y) and (Y)-[:NARROWER_THAN]->(Z), then we may want to get rid of any (X)-[:NARROWER_THAN]->(Z) as it is kind of redundant. But this is an optional step that you may or may not want to include.
MATCH (g1)-[:NARROWER_THAN*2..]->(g3),
(g1)-[d:NARROWER_THAN]->(g3)
DELETE d
So that’s it! Here is the taxonomy:

A couple of interesting examples:
- military-science-fiction << space-opera << science-fiction
- nutrition << health << non-fiction
Worth mentioning that while these are true in our dataset, as our graph grows and evolves over time, we may find contradictions to them that would invalidate the taxonomy so as data evolves it will make sense to re-compute the taxonomy creation.
Using the taxonomy
The objective of learning how a set of tags relate was to then be able to use it in some meaningful way. The CO_OCCURS relationship in itself is a useful one as it indicates some degree of overlap between tags and therefore a certain degree of similarity. But NARROWER_THAN has stronger semantics, let’s see how could we use it:
One possible use would be to recommend books based on the taxonomy we’ve just learned. This first query lists available subcategories with the number of items in them
MATCH (b:Book) WHERE b.title = 'Slow Bullets'
MATCH (b)-[:HAS_GENRE]->(g)<-[:NARROWER_THAN]-(childGenre)
WHERE size((g)<-[:HAS_GENRE]-()) < 500 AND NOT (b)-[:HAS_GENRE]->()-[:NARROWER_THAN]->(g)
AND NOT (b)-[:HAS_GENRE]->(childGenre)
RETURN "Hello! '" + b.title + "' is tagged as '" + g.name + "', and we have " + size((childGenre)<-[:HAS_GENRE]-()) + " books on '" + childGenre.name + "' which is a narrower category. Want to have a look? " AS recommendationQuestion
When run on ‘Pride and Prejudice’ it produces this output:

Actually it does a bit more than just that, if we analyse the Cypher, we can see that we start from a selected book and for each genre with less than 500 books in it -we want to exclude large ones like ‘fiction’ as they are too generic to provide relevant recommendations- we get the sub-categories that the current book is not tagged as. We also stop the generation of sub-category based recommendations if there is already a sibling subcategory in the tags of the selected book. Basically, if a book is tagged as ‘sports’ and ‘tennis’, tennis being a subcategory of sports, we will not recommend other subcategories of sports like ‘hockey’ or ‘football’. Yes, all that in 5 lines of cypher! Anyway, this is just one possible query that uses the hierarchy and that makes sense in my data set but you may want to tune it to yours.
And this second query, very similar to the previous one, lists the actual items in the subcategory:
MATCH (b:Book) WHERE b.title = {title}
MATCH (b)-[:HAS_GENRE]->(g)<-[:NARROWER_THAN]-(childGenre)
WHERE size((g)<-[:HAS_GENRE]-()) < 500 AND NOT (b)-[:HAS_GENRE]->()-[:NARROWER_THAN]->(g) AND NOT (b)-[:HAS_GENRE]->(childGenre)
WITH childGenre
MATCH (booksInChildCategory)-[:HAS_GENRE]->(childGenre)
RETURN booksInChildCategory.title AS bookTitle, substring(booksInChildCategory.description,1, 70) + '...' AS description
We can run it this time on ‘Slow Bullets’ and it will produce:

Notice that both queries are neutral from the point of view of what’s in the taxonomy, as the taxonomy evolves over time, the results will be different.
Of course, recommendation can get a lot more complicated but this is just a basic suggestion on how the taxonomy could be used. Another option is to use the NARROWER_THAN in combination with the CO_OCCURS for richer recommendations in case there are no NARROWER_THAN alternatives. More on this in future blog posts.
What’s interesting about this QuickGraph?
This is a basic attempt at analysing tag co-occurrence using a graph. The algorithm can be refined in a number of ways but I thought it would be interesting to share it in its basic form and maybe blog later on on how to improve it.
I think the most interesting is the fact that the approach is generic and can be used in many contexts to build a purely dynamic and automated solution. The taxonomy creation algorithm can be re-run on a regular basis as new tagged data is added to the graph and the logic (like the one described in the “using the taxonomy” section) will produce results adapted to the fresh version of the taxonomy.
It’s worth mentioning that the quality of the hierarchy will directly depend on the quality of your data tagging! We are not creating a formal ontology here but rather building a pragmatic and actionable taxonomy derived in an automated way from your data.
Watch this space for other examples of use of this approach and some suggested refinements.
I’d also love to get your feedback!
Quick note on getting the data
To get some data from Goodreads your best option is to write some code using their API. Other alternatives are for instance import.io (click to try the import.io ‘lightning’ scraper on a GoodReads list) or HTML scraping libraries for your favourite programming language, rvest if you’re an R fan or Beautiful Soup or lxml if you prefer python.
If you want to test the algorithm on your Neo4j instance with the same dataset I used you just need to run the data load scripts above, they include the link to the data.

This example has been really useful.
Just a little fix, it should be “substring(booksInChildCategory.description,0, 70)”, and not “1, 70”.
LikeLike
Good catch, Lostu. Thanks for the heads up. Actually I see that in the screen capture the first letter is cut off 🙂
Happy to hear you found the post useful. Now spread the word and share your experience 😉
LikeLike
I really enjoyed reading your interesting quick graph articles, especially this one. While using this approach I noticed that there are less narrower-than relationships than I expected. I figured out that the cause is located in the condition of the statement for creating these relationsships: “ID(g1) > ID(g2)”. I suppose you adapted this condition from statement for creating same-as relationsships. For the same-as relationsships this makes sense because you only need one relation for both “directions” but when creating narrower-than relationships all relationsships omitted where g2 has a smaller ID than g1 but an index value of “1”.
Changing this stament to:
MATCH (g1)-[co1:CO_OCCURS]->(g2),
(g2)-[co2:CO_OCCURS]->(g1)
WHERE ID(g1) ID(g2)
AND co1.index = 1 and co2.index (g2)
solves this problem for me and I got a lot more narrower-than relationsships than before. Maybe your category taxonomy would be also richer when rerunning the process with this change 😉
LikeLike
Seems that the markup removes the inequality sign. The fixed condition should be “WHERE ID(g1) unequal ID(g2)” where unequal is “”.
LikeLike
Hey Tino, thanks for your interest. You’re absolutely right there’s no reason to apply the filter in the second case. Nice catch!
Thanks a lot.
I’ve updated teh code with your suggestion. I’ve not tried to re-run the whole example though.
FYI, now you can run the first part (overlap similarity computation) using the GDS library. Here’s a link to the manual: https://neo4j.com/docs/graph-data-science/current/alpha-algorithms/overlap/#alpha-algorithms-similarity-overlap
LikeLiked by 1 person
You are welcome! Right, the condition can even omitted. Seems that something went wrong on your code update. The code now looks broken (example code STEP 4).
Thanks for pointing me to the Overlap Similarity algorithm. I will try this soon.
LikeLike
Sorry, I mean the example code in STEP 3 is now broken.
LikeLiked by 1 person
Ups! I don’t know what happened. I think it’s fixed now. Thanks again 🙂
LikeLike
Loved readding this thank you
LikeLike
thanks! glad to hear that 🙂
LikeLike