After last week’s Neo4j online meetup, I thought I’d revisit QuickGraph#2 and update it a bit to include a couple new things:
- How to load not only categories but also pages (as in Wikipedia articles) and enrich the graph by querying DBpedia. In doing this I’ll describe some advanced usage of APOC procedures.
- How to batch load the whole Wikipedia hierarchy of categories into Neo4j
Everything I explain here will also go into an interactive guide that you can easily run from your Neo4j instance. Or why not giving it a try in the Neo4j Sandbox?
All you have to do is run this on your Neo4j browser:
:play https://guides.neo4j.com/wiki
For a description of the Wikipedia data and the MediaWiki API, check QuickGraph#2.
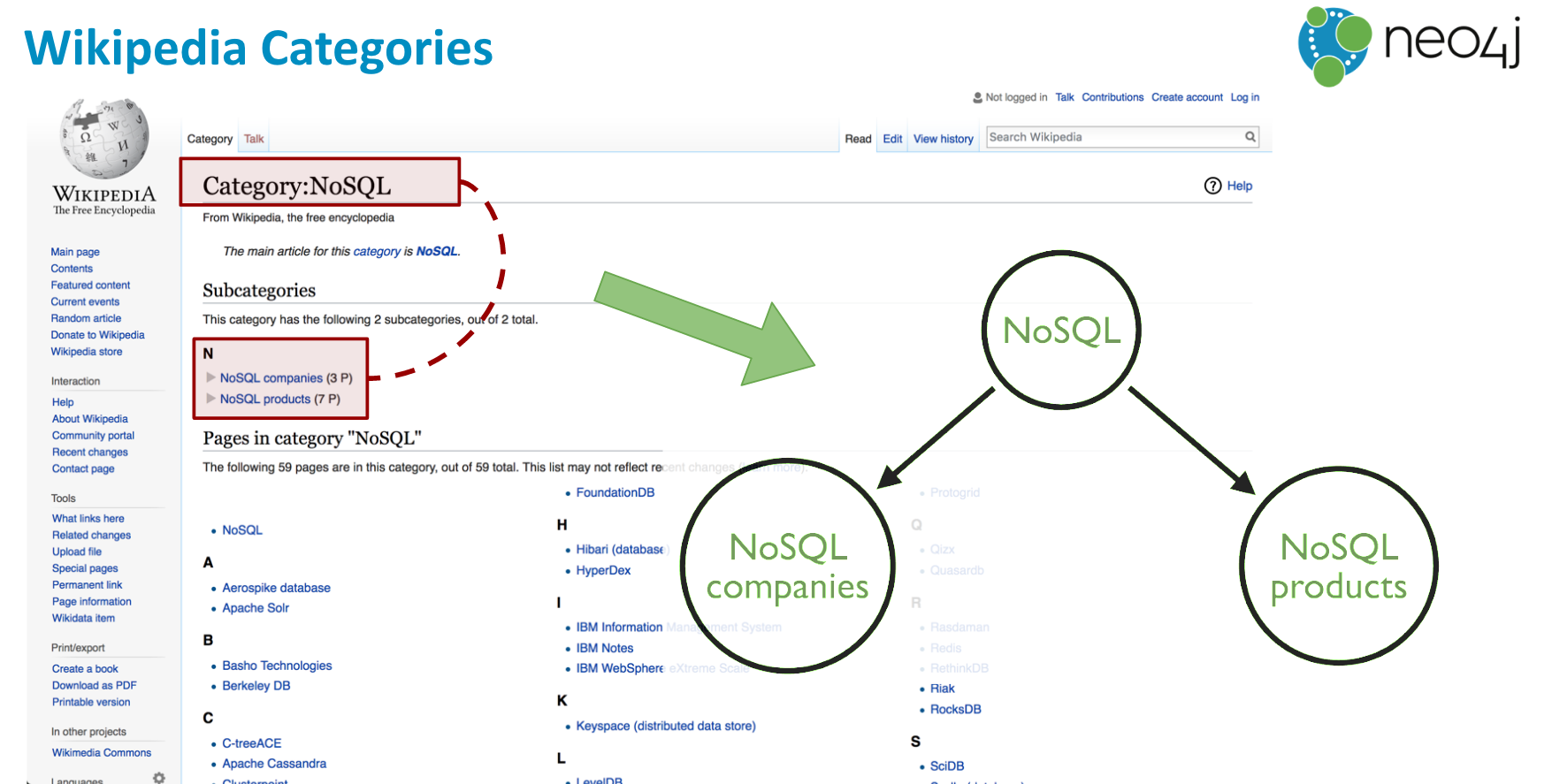
Loading the data into Neo4j
First, let’s prepare the DB with a few indexes to accelerate the ingestion and querying of the data:
CREATE INDEX ON :Category(catId)
CREATE INDEX ON :Category(catName)
CREATE INDEX ON :Page(pageTitle)
Approach 1: Loading a reduced subset incrementally through the MediaWiki API
This approach uses the WikiMedia API and is adequate if all you want is a portion of the category hierarchy around a particular topic. Let’s say we want to create the Wikipedia Knowledge Graph about Databases.
The first thing we’ll do is create the root category: Databases.
CREATE (c:Category:RootCategory {catId: 0, catName: 'Databases', subcatsFetched : false, pagesFetched : false, level: 0 })
Now we’ll iteratively load the next level of subcategories to a depth of our choice. I’ve selected only three levels down from the root.
UNWIND range(0,3) as level
CALL apoc.cypher.doit("
MATCH (c:Category { subcatsFetched: false, level: $level})
CALL apoc.load.json('https://en.wikipedia.org/w/api.php?format=json&action=query&list=categorymembers&cmtype=subcat&cmtitle=Category:' + apoc.text.urlencode(c.catName) + '&cmprop=ids%7Ctitle&cmlimit=500')
YIELD value as results
UNWIND results.query.categorymembers AS subcat
MERGE (sc:Category {catId: subcat.pageid})
ON CREATE SET sc.catName = substring(subcat.title,9),
sc.subcatsFetched = false,
sc.pagesFetched = false,
sc.level = $level + 1
WITH sc,c
CALL apoc.create.addLabels(sc,['Level' + ($level + 1) + 'Category']) YIELD node
MERGE (sc)-[:SUBCAT_OF]->(c)
WITH DISTINCT c
SET c.subcatsFetched = true", { level: level }) YIELD value
RETURN value
Once we have the categories, we can load the pages in a similar way:
UNWIND range(0,4) as level
CALL apoc.cypher.doit("
MATCH (c:Category { pagesFetched: false, level: $level })
CALL apoc.load.json('https://en.wikipedia.org/w/api.php?format=json&action=query&list=categorymembers&cmtype=page&cmtitle=Category:' + apoc.text.urlencode(c.catName) + '&cmprop=ids%7Ctitle&cmlimit=500')
YIELD value as results
UNWIND results.query.categorymembers AS page
MERGE (p:Page {pageId: page.pageid})
ON CREATE SET p.pageTitle = page.title, p.pageUrl = 'http://en.wikipedia.org/wiki/' + apoc.text.urlencode(replace(page.title, ' ', '_'))
WITH p,c
MERGE (p)-[:IN_CATEGORY]->(c)
WITH DISTINCT c
SET c.pagesFetched = true", { level: level }) yield value
return value
Notice that we are only loading the id and the title for each page. This is because the MediaWiki API only exposes metadata about pages, but we can get some extra information on them from the DBpedia. DBpedia is a crowd-sourced community effort to extract structured information from Wikipedia and make this information available on the Web.
There is a public instance of the DBpedia that exposes an SPARQL endpoint that we can query to get a short description of a given Wikipedia page. The Cypher fragment below embeds the SPARQL query that’s sent to the endpoint.
WITH "SELECT ?label
WHERE {
?x <http://xmlns.com/foaf/0.1/isPrimaryTopicOf> <@wikiurl@> ;
<http://dbpedia.org/ontology/abstract> ?label .
FILTER(LANG(?label) = '' || LANGMATCHES(LANG(?label), 'en')) } LIMIT 1
" AS sparqlPattern
UNWIND range(0,3) as level
CALL apoc.cypher.doit("
MATCH (c:Category { level: $level })<-[:IN_CATEGORY]-(p:Page)
WHERE NOT exists(p.abstract)
WITH DISTINCT p, apoc.text.replace(sparqlPattern,'@wikiurl@',p.pageUrl) as runnableSparql LIMIT 100
CALL apoc.load.json('http://dbpedia.org/sparql/?query=' + apoc.text.urlencode(runnableSparql) + '&format=application%2Fsparql-results%2Bjson') YIELD value
SET p.abstract = value.results.bindings[0].label.value
", { level: level, sparqlPattern: sparqlPattern }) yield value
return value
I’ve limited to 100 pages per level because we are generating an HTTP request to the DBpedia endpoint for each Page node in our graph. Feel free to remove this limit but keep in mind that this can take a while.
Ok, so we have our Wikipedia Knowledge Graph on Databases and we can start querying it.
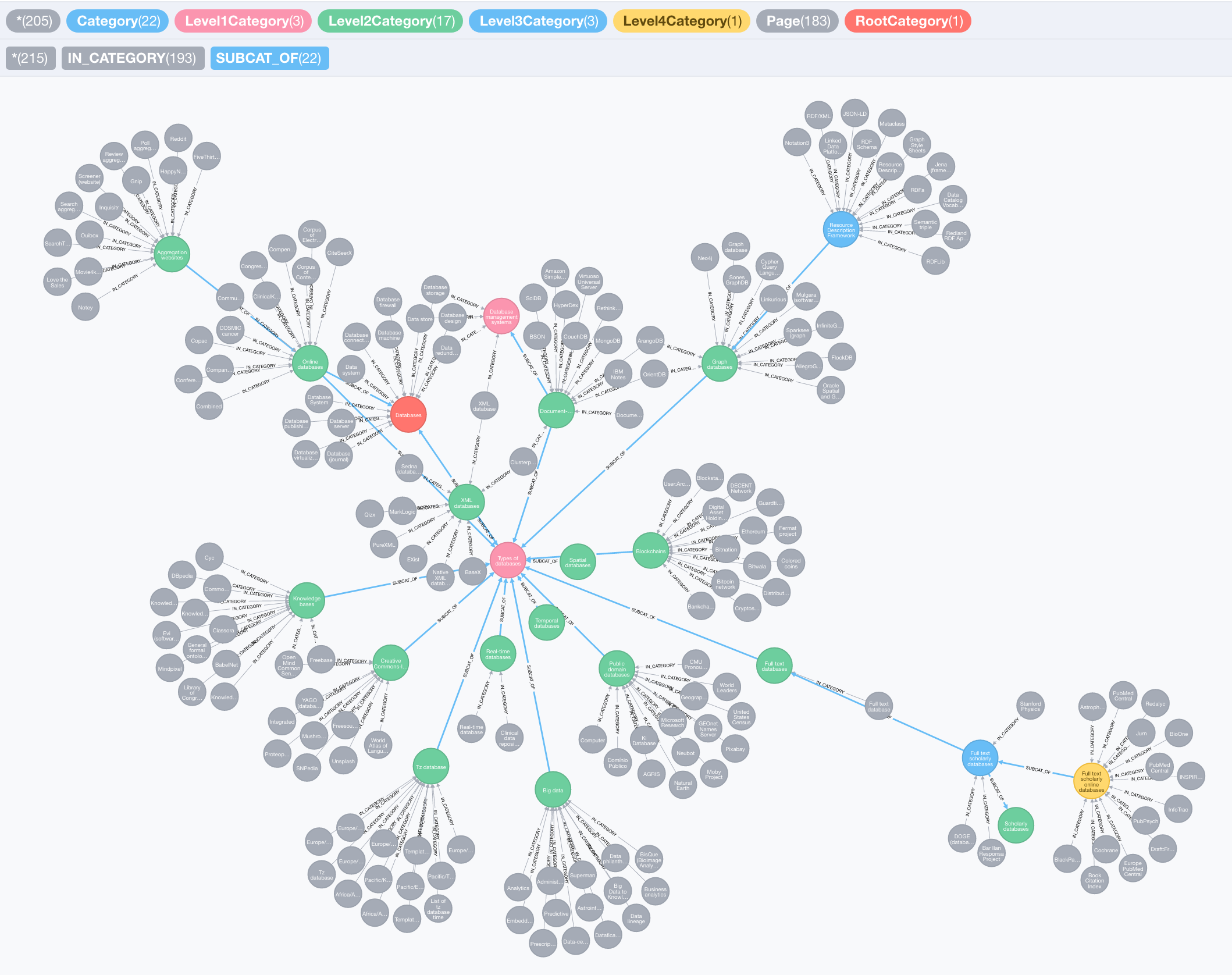
Querying the graph
We can list categories by the number of sub/super categories or by the number of pages. We can also create custom indexes like the balanceIndex below that tells us how ‘balanced’ (ratio between supercategories and subcategories) a category is. Closer to zero are the more balanced categories and closer to one are the more unbalanced.
MATCH (c:Category) WITH c.catName AS category, size((c)<-[:SUBCAT_OF]-()) AS subCatCount, size((c)-[:SUBCAT_OF]->()) AS superCatCount, size((c)<-[:IN_CATEGORY]-()) AS pageCount WHERE subCatCount > 0 AND superCatCount > 0 RETURN category, pageCount, subCatCount, superCatCount, ABS(toFloat(superCatCount - subCatCount)/(superCatCount + subCatCount)) as balanceIndex ORDER BY subCatCount DESC LIMIT 500
We can also aggregate these values to produce stats on our Knowledge Graph
MATCH (c:Category) WITH c.catName AS category, size((c)<-[:SUBCAT_OF]-()) AS subCatCount, size((c)-[:SUBCAT_OF]->()) AS superCatCount, size((c)<-[:IN_CATEGORY]-()) AS pageCount, size((c)-[:SUBCAT_OF]-()) AS total RETURN AVG(subCatCount) AS `AVG #subcats`, MIN(subCatCount) AS `MIN #subcats`, MAX(subCatCount) AS `MAX #subcats`, percentileCont(subCatCount,0.9) AS `.9p #subcats`, AVG(pageCount) AS `AVG #pages`, MIN(pageCount) AS `MIN #pages`, MAX(pageCount) AS `MAX #pages`, percentileCont(pageCount,0.95) AS `.9p #pages`, AVG(superCatCount) AS `AVG #supercats`, MIN(superCatCount) AS `MIN #supercats`, MAX(superCatCount) AS `MAX #supercats`, percentileCont(superCatCount,0.95) AS `.9p #supercats`

Approach 2: Batch loading the data with LOAD CSV from an SQL dump
There is a snapshot of the Wikipedia categories and their hierarchical relationships (as of mid-April 2017) here. It contains 1.4 million categories and 4 million hierarchical relationships. They can both be loaded into Neo4j using LOAD CSV. You can run the queries as they are or download the files to your Neo4j’s instance import directory and use LOAD CSV FROM "file:///..." instead.
First the categories. Notice that we are loading a couple of extra properties in the Category nodes: the pageCount and the subcatCount. These numbers are a precomputed in the data dump and not always accurate.
USING PERIODIC COMMIT 10000
LOAD CSV FROM "https://github.com/jbarrasa/datasets/blob/master/wikipedia/data/cats.csv?raw=true" as row
CREATE (c:Category { catId: row[0]})
SET c.catName = row[2], c.pageCount = toInt(row[3]), c.subcatCount = toInt(row[4])
And then the subcategory relationships
USING PERIODIC COMMIT 10000
LOAD CSV FROM "https://github.com/jbarrasa/datasets/blob/master/wikipedia/data/rels.csv?raw=true" as row
MATCH (from:Category { catId: row[0]})
MATCH (to:Category { catId: row[1]})
CREATE (from)-[:SUBCAT_OF]->(to)
If you’re interested in regenerating fresh CSV files, here’s how:
- Start by downloading the latest DB dumps from the Wikipedia downloads page.
For the category hierarchy, you’ll only need the following tables: category, categorylinks and page. - Load them in your DBMS.
- Generate the categories CSV file by running the following SQL
select p.page_id as PAGE_ID, c.cat_id as CAT_ID, cast(c.cat_title as nCHAR) as CAT_TITLE , c.cat_pages as CAT_PAGES_COUNT, c.cat_subcats as CAT_SUBCAT_COUNT into outfile '/Users/jbarrasa/Applications/neo4j-enterprise-3.1.2/import/wiki/cats.csv' fields terminated by ',' enclosed by '"' escaped by '\\' lines terminated by '\n' from test.category c, test.page p where c.cat_title = p.page_title and p.page_namespace = 14
- Generate the relationships file by running the following SQL
select p.page_id as FROM_PAGE_ID, p2.page_id as TO_PAGE_ID into outfile '/Users/jbarrasa/Applications/neo4j-enterprise-3.1.2/import/wiki/rels.csv' fields terminated by ',' enclosed by '"' escaped by '\\' lines terminated by '\n' from test.category c, test.page p , test.categorylinks l, test.category c2, test.page p2 where l.cl_type = 'subcat' and c.cat_title = p.page_title and p.page_namespace = 14 and l.cl_from = p.page_id and l.cl_to = c2.cat_title and c2.cat_title = p2.cat_title and p2.page_namespace = 14
What’s interesting about this QuickGraph?
It showcases interesting usages of procedures like apoc.cypher.doit to run Cypher fragments within our query or apoc.load.json to interact with APIs producing JSON results.
Rich category hierarchies like the one in Wikipedia are graphs and extremely useful for recommendation or graph-enhanced search. Have a look at the queries in QG#2 and the ones in the interactive guide for some ideas.
:play https://guides.neo4j.com/wiki

If you have this errror:
Neo.ClientError.Procedure.ProcedureNotFound: There is no procedure with the name `apoc.cypher.doit` registered for this database instance. Please ensure you’ve spelled the procedure name correctly and that the procedure is properly deployed.
Change the procedure from ‘apoc.cypher.doit’ to ‘apoc.cypher.doIt’ .
LikeLike
Thanks for your comment, Daniel. Also here’s the link to the ‘doIt’ procedure documentation: https://neo4j-contrib.github.io/neo4j-apoc-procedures/#_running_cypher_fragments
LikeLike
Thank you very much for the great job 🙂
LikeLike