In this second post on WordNet on Neo4j I will be focusing on querying and analysing the graph that we created in the previous post. I’ll leave for a third instalment some more advanced analysis and maybe integrations with NLTK or RDF.
Remember that you can test all the examples in this post directly on the demo server. The access credentials are wordnet/wordnet (also you’ll need to select the database of the same name). I’ve also put the queries in a Colab python notebook if you prefer to run them from there.
Let’s crack on.
Some general queries
The main graph pattern in WordNet is “Form – Lexical Entry – Lexical Sense – Lexical Concept” and we can use it to run a number of general queries in the graph.

One great thing about graph models in Neo4j is that the definition of patterns using the Cypher query language feels like drawing the graph in your head using ascii art. Here’s what a Cypher pattern for the previous graph would look like:

Neat, right? Well, let’s start with a simple one. Let’s use the pattern to get the more “ambiguous” words in the language. Or in other words, the ones that have more possible senses:
Most polysemic words
We can easily get the top ten by running the following query. Just a portion of the previous pattern will give us a list of lemmas and sense counts in tabular form:
MATCH (lemma:ontolex__Form)
RETURN lemma.ontolex__writtenRep as lemma,
size((lemma)<-[:ontolex__canonicalForm]-(:ontolex__LexicalEntry)-[:ontolex__sense]->()) as senseCount
ORDER BY senseCount DESC LIMIT 10Which unsurprisingly will give us “break”, “cut”, “run”, “play”… and all these english words that are present in one way or another in practically every sentence…

After looking at the counts, we might be interested in diving into a specific word and find all its possible meanings and get them presented as a graph. Here’s the query that returns the subgraph with all the meanings for the lemma “clear”:
MATCH path = (lemma:ontolex__Form)<-[:ontolex__canonicalForm]-(:ontolex__LexicalEntry)-[:ontolex__sense]->()-[:ontolex__isLexicalizedSenseOf]->()
WHERE lemma.ontolex__writtenRep = "clear"
RETURN path
Or if you want them as a table, then your query would be this one:
MATCH path = (le:ontolex__LexicalEntry { ontolex__canonicalForm: "clear"})-[:ontolex__sense]->(s)-[:ontolex__isLexicalizedSenseOf]->(con)
RETURN le.wn__partOfSpeech AS PoS, con.wn__definition AS definition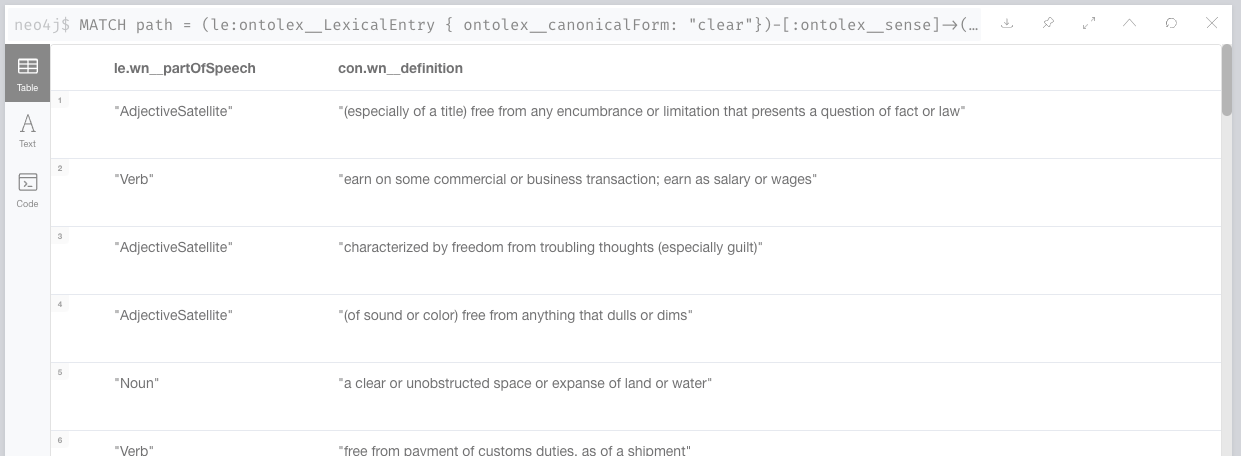
Lexical concepts with many words to express them
It gets more interesting when we traverse our pattern in the opposite direction. Let’s say I want to start from a concept and find all the words in English language that can be used to express it. Here are the three ways of expressing the concept “being unsuccessful”:
MATCH path = (:ontolex__Form)<-[:ontolex__canonicalForm]-(:ontolex__LexicalEntry)-[:ontolex__sense]->(s)-[:ontolex__isLexicalizedSenseOf]->(con:ontolex__LexicalConcept { wn__definition : "be unsuccessful" })
RETURN path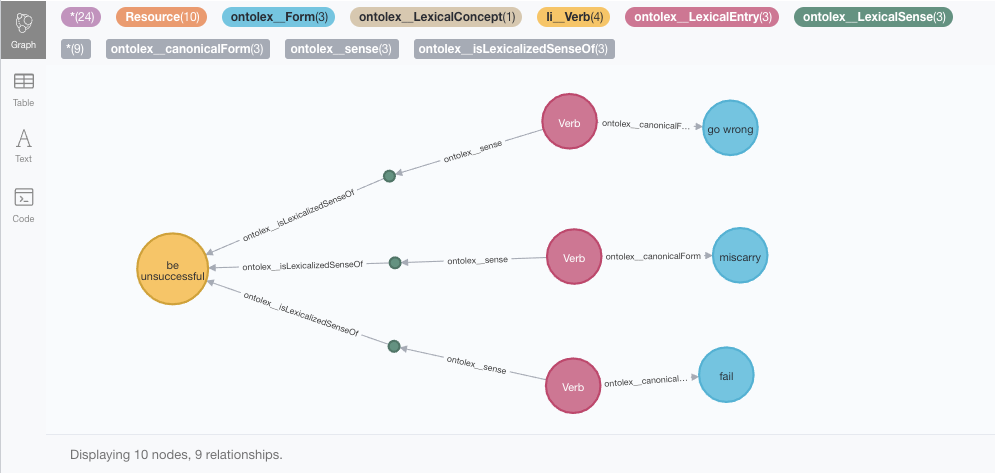
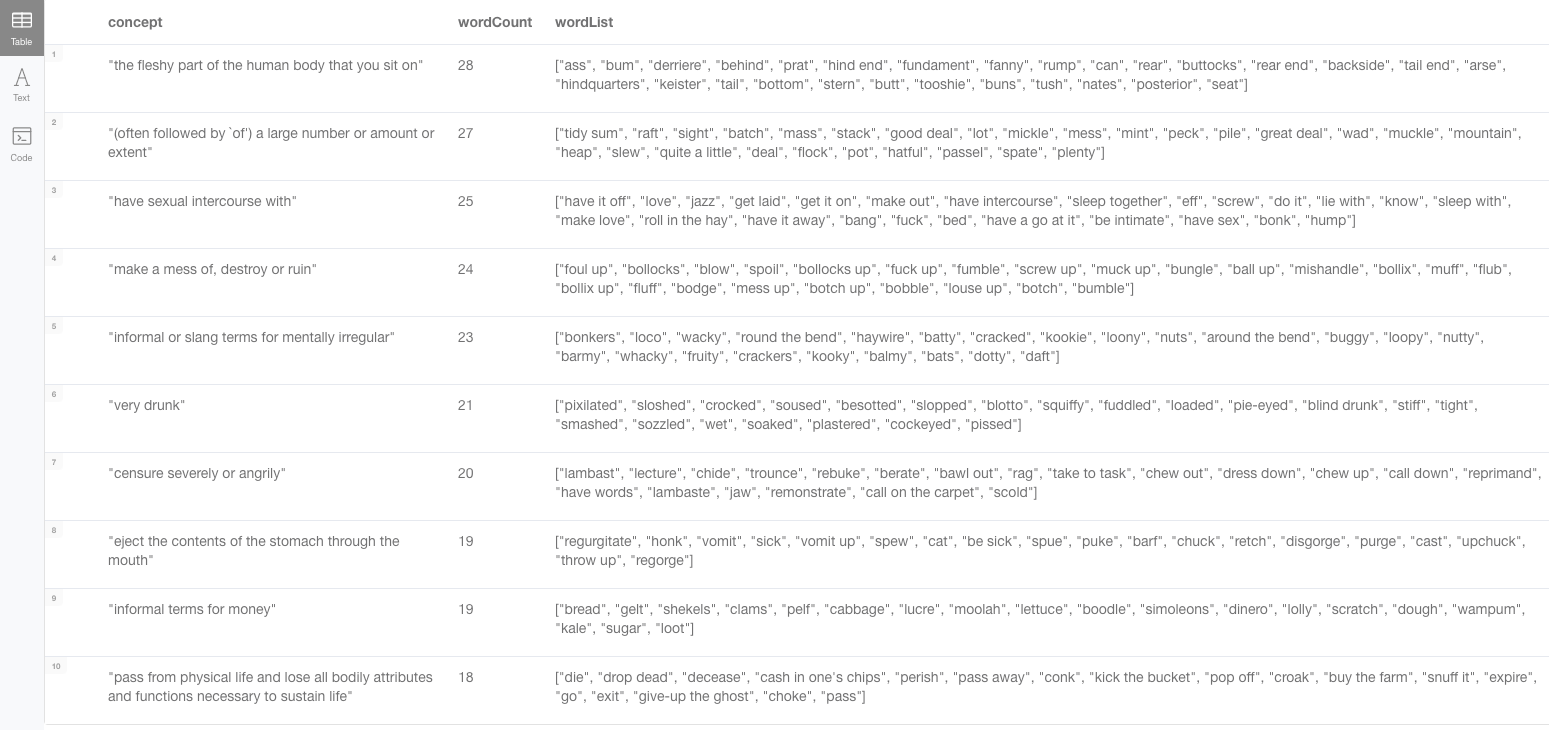
I’m sure you’re asking yourself which are the concepts with more words to express them? At least I was when I was doing this analysis. Well, the answer is quite amusing. Here is the query that would return the top ten:
MATCH (concept:ontolex__LexicalConcept)<-[:ontolex__isLexicalizedSenseOf]-()<-[:ontolex__sense]-(:ontolex__LexicalEntry)-[:ontolex__canonicalForm]->(lemma)
RETURN concept.wn__definition as concept, count(distinct lemma.ontolex__writtenRep) as wordCount
ORDER BY wordCount DESC LIMIT 10and here are the winners. Enjoy!
What about concepts that have one and only one word to express them? You could just invert the ordering (removing the DESC) in the previous query and you would get a bunch of them. Or you can specifically look for them with this variant of the query that puts the focus on nouns:
MATCH (concept:ontolex__LexicalConcept:li__Noun) WHERE size((concept)<-[:ontolex__isLexicalizedSenseOf]-()) = 1
RETURN concept.wn__definition as c, concept.wn__partOfSpeech as pos, [(concept)<-[:ontolex__isLexicalizedSenseOf]-()<-[:ontolex__sense]-(le:ontolex__LexicalEntry) | le.ontolex__canonicalForm] as word
ORDER BY size((concept)--()) LIMIT 100And you would get results like “ideally perfect state; especially in its social and political and moral aspects” and its single lexicalized form, which is… you guessed it: “utopia”.
Semantic relationships between Lexical Concepts
You may have noticed that there is a large number of relationships in the graph that we have not explored yet. I will not enumerate or use them all here. You can get a list of them all in neo4j running:
CALL db.relationshipTypes()I also found this post very useful explaining all these terms, some of which I had never heard before.
One of the simpler ones is the hypernym/hyponym relationship between lexical concepts, meaning more generic and more specific respectively. These relationships when chained, form a taxonomy of lexical concepts.
This query will return all the hyponyms of a given lexical concept
MATCH path = (moreSpecific)-[:wn__hypernym*]->(con:ontolex__LexicalConcept { wn__definition : $definition })
RETURN pathWhen we apply it to “being unsuccessful” we can see that there is a constellation of nodes actually representing more specific ways of being unsuccessful:

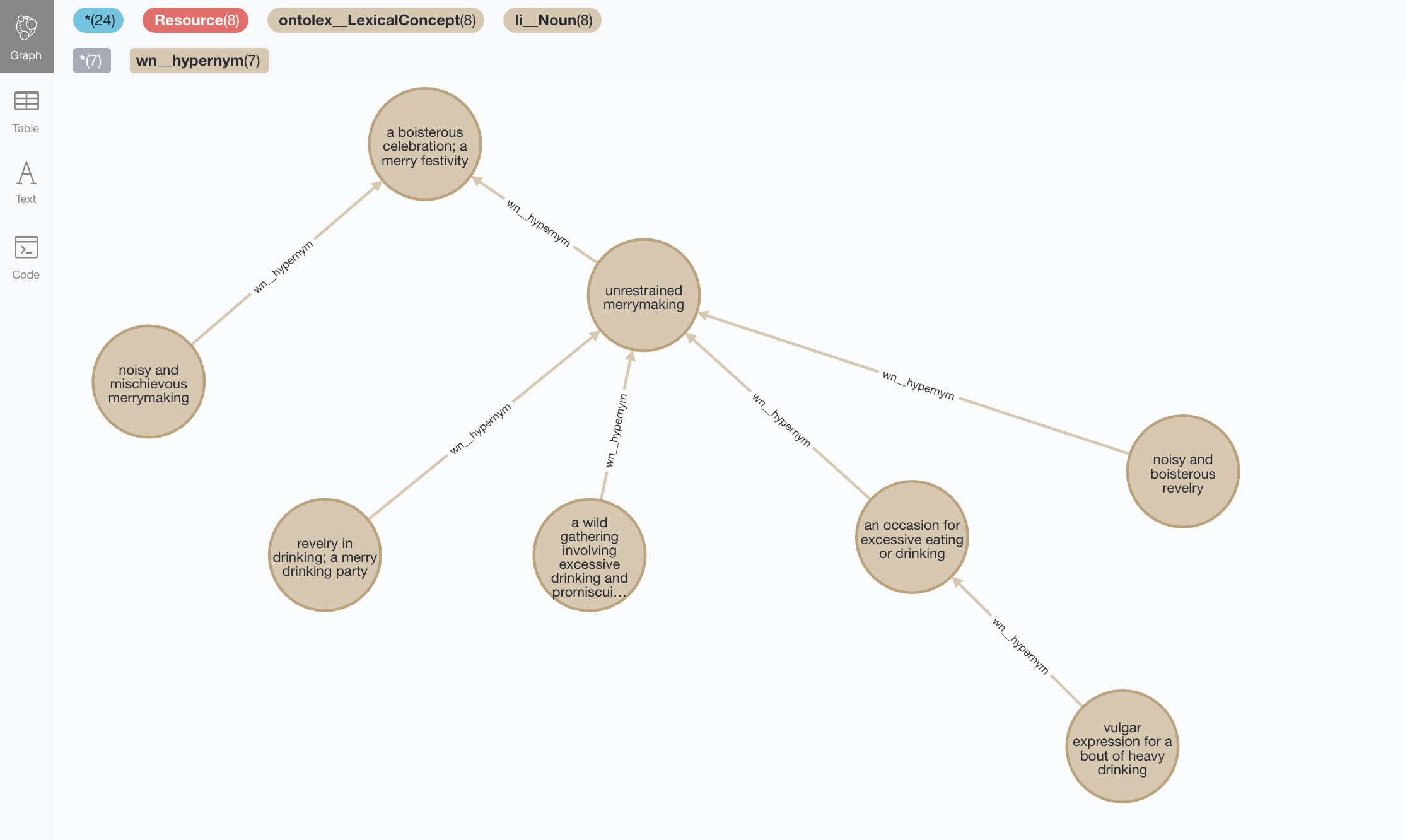
But when applied to a more generic term like “a boisterous celebration; a merry festivity” will produce a richer (and deeper) taxonomy. Note that the asterisk in the relationship pattern -[:wn__hypernym*]-> indicates that we want to jump a variable number of hops, or in other words go as deep as the hierarchy goes:
What about combining the last two query types? Let’s say I want to get all the ways to express the concept “being unsuccessful” or any of the more specific variant (hyponyms) of the concept? I could get a much richer set of words, and from the query point of view it will be just a case of merging the two patterns. Here’s your query
MATCH path = (:ontolex__Form)<-[:ontolex__canonicalForm]-(le:ontolex__LexicalEntry)-[:ontolex__sense]->()-[:ontolex__isLexicalizedSenseOf]->()-[:wn__hypernym*0..]->(con:ontolex__LexicalConcept { wn__definition : "be unsuccessful" })
RETURN pathwhich will produce a nice graph view in your browser like the one I posted earlier this week
or if you want to return your results as a list including the type of word as well (Part of Speech) you can modify the previous query as follows:
MATCH (lemma:ontolex__Form)<-[:ontolex__canonicalForm]-(le:ontolex__LexicalEntry)-[:ontolex__sense]->()-[:ontolex__isLexicalizedSenseOf]->(concept)-[:wn__hypernym*0..]->(:ontolex__LexicalConcept { wn__definition : "be unsuccessful" })
RETURN lemma.ontolex__writtenRep as lemma, le.wn__partOfSpeech as PoS, concept.wn__definition as definition ORDER BY definitionProducing a list starting like this:

Path Queries
I’ll conclude this second instalment with some path analysis on WordNet. As you know, we can easily get the shortest path between two nodes in neo4j using the shortestPath function. But what can a path between two words mean in WordNet? Let’s find out.
If we explore the shortest path between the words good and bad, we notice that they are quite close to each other. The length of the shortest path connecting them is low, but if we look at the detail, we see that the path in question traverses the antonym relationship. Which makes them not only related words but also somehow opposite words.

Let’s try to formalise this simple hypothesis in a query: distance in the graph and presence/absence of antonym relationship as indicators of word proximity and opposite meaning. For a first iteration, we can go with a blind path exploration, which means the path can travers any relationship (see red section in the query below).
The length of the path (green) can be computed using the length function in cypher. Notice that I’ve adjusted it by subtracting 4 to it which is the minimum distance between any two words in the graph given the pattern “Form > LexicalEntry > LexicalSense”. But this is obviously entirely optional.
Finally a simple way of detecting whether the path includes an antonym edge is by iterating over the types of the relationships in the path (orange block).

Let’s see if it produces anything meaningful. I’ve modified the query so that it takes a list of pairs of words as input. Also instead of returning the whole path, which is great for visualisation in the browser or in Bloom, in this variant I’ve added a fragment that transforms the path into a string (explain column) which is better when returning tabular results.
UNWIND $wordPairs as pair
MATCH (w1:ontolex__Form { ontolex__writtenRep: pair.word1 }),(w2:ontolex__Form { ontolex__writtenRep: pair.word2 })
MATCH path = shortestPath((w1)-[*]-(w2))
WITH pair.word1 as word1, pair.word2 as word2, length(path) as rawLength,
size([x in relationships(path) where type(x) contains "antonym"]) as ac,
apoc.text.join([x in nodes(path) | coalesce(x.ontolex__canonicalForm,"") + coalesce(x.wn__definition,"")]," -> ") as explain
RETURN word1, word2, rawLength - 6 + 2 * ac as distance, ac as antonym_count, explain
ORDER BY distanceIf you feed the query with this input (a rather random list of pairs of words):
:param wordPairs: [ { word1: "good", word2: "bad"},{ word1: "good", word2: "nice"},{ word1: "dog", word2: "house"},
{ word1: "cat", word2: "tiger"},{ word1: "house", word2: "pet"},{ word1: "dog", word2: "pet"},{ word1: "love", word2: "hate"},{ word1: "love", word2: "spoon"},{ word1: "love", word2: "screwdriver"},
{ word1: "happy", word2: "joyful"},{ word1: "hapy", word2: "indifferent"},{ word1: "music", word2: "happiness"}]you should get these results:

It’s not entirely wrong for being the most naive approach, right? good is close to bad, although they’re opposites, just as love and hate, also good is close to nice, and cat is close to tiger. Just a comment on a couple of unintuitive results (highlighted in yellow in the results):
- I would not have expected “love” to be closer to “spoon” than it is to “screwdriver” but… there happens to be a sense of the word “spoon” that is a lot closer to “love” than the kitchen utensil 🙂 The answer is in the explain column.
- The interpretation we are getting for “house” and “pet” is very different from the one I intended. I was expecting to explore the connection between a domesticated animal and the building where one lives… but we are getting that between a “horoscope house” and a “special loved one”
Anyway, it was obviously not a scientific approach at all, but I’m happy if I’ve piqued your interest to explore the idea further and also to realise that looking at any dataset as a graph opens many new ways of exploring it.
Things that I would consider would be giving weights to different relationships and apply a path exploration algo like Dijkstra that uses the weights in the relationships. Or maybe use similarity algorithms like jaccard or overlap (both described here) to see if they’re good predictors of word proximity.
I would expect the results to be strongly influenced by the richness of the relationships between lexical concepts in WordNet but nothing stops you from enriching it with your own relationships 😉
Also don’t forget that in my example I analyse words, not concepts, that’s why some results were unexpected but again, you could modify this and work concept proximity instead of word proximity.
What’s interesting about this quick graph?
There’s this idea that has been in my head for a while now: which (and how many) questions are we not asking our data? When data is stored in a document DB or in an RDBMS, the formalism (tables, documents,…) implicitly guides us into a predetermined way of analysing it. But when we represent our data points as interconnected nodes in a graph, there is no predefined entry point for analysis. You can basically ask any question from any angle. Actually the graph reveals new ways to query and explore your data that would have been much harder to come up with when using other data representations.
An example of this is this conversation that I started in twitter a few days ago:
When I thought of exploring the inverse of the polysemy pattern, that is “concepts with multiple words to express them” instead of “words with multiple meanings (polysemy)”, I was surprised because I could not find a term to describe it (a polywordy concept?). It actually probably does not exist and that’s exactly my point, it’s probably an unusual or somehow unexpected way of exploring the data.
Extrapolate this to any area of your data work. Possibilities are endless!
I know there are many more ways of analysing the data, I’ll try to come up with more ideas for the next post, but I’m also happy to take suggestions. Oh, and I’ve not forgotten about the publishing your graph as RDF, we’ll cover that too. See you soon for part three and as always, give this all a try and let us know how it goes in the neo4j community site.

Hello Jesús,
You wrote “When data is stored in a document DB or in an RDBMS, the formalism (tables, documents,…) implicitly guides us into a predetermined way of analysing it. But when we represent our data points as interconnected nodes in a graph, there is no predefined entry point for analysis. You can basically ask any question from any angle.” In your opinion, is “Virtual Graph” a valid approach to achieve this Graph representation for RDB? I’m asking because it has many advantages like, although the actual data is still stored in the RDB, GraphQL queries can be used. What I’m not sure about is if the analytic algorithms, like “Topological Similarity” or “Community Detection”, can be used in a “Virtual Graph”. Is it also possible? Thanks in advance for your reply.
LikeLike