Neosemantics (n10s) has been supporting RDF* for a few months now (from release 4.1.0, Sep 2020). Around the time of the release we did a live coding session going over some of the new features, one of which was RDF*. I thought I’d put a couple of examples in a quick graph similar to the ones in the video session to make it easier for people to find and give it a try. This is what you’re reading right now.
Level of support of RDF* in n10s
In the draft Community Group Report of 15 January 2021, RDF* triples are defined as triples that include a triple as a subject or an object. This translates into a number of new modelling possibilities one of which is the possibility to offer a simple way to represent properties of relationships.
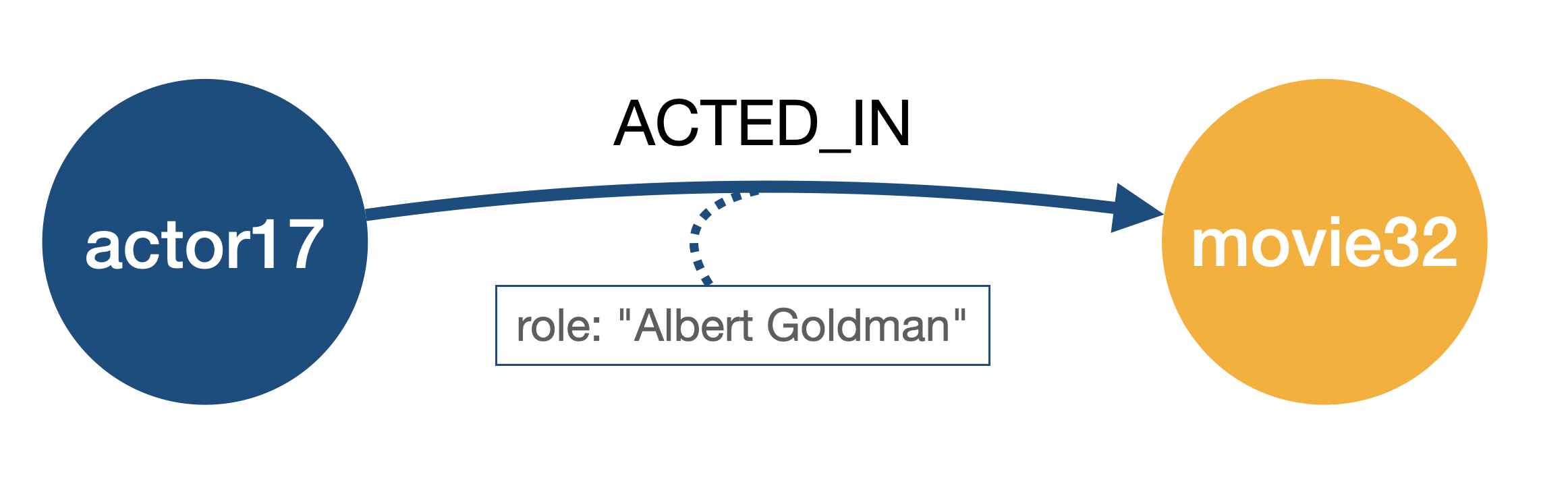
This is precisely the use supported by n10s: In formal terms, n10s supports RDF* triples that have a triple as subject and a literal as object. The inner triple represents a relationship and the outer triple represents a property of that individual relationship. Here’s an example of these kind of triples:
<<:actor17 n4sch:ACTED_IN :movie32>> n4sch:role "Albert Goldman" .Which effectively represents the following scenario
Export: Serialising a Neo4j database as RDF*
RDF* makes it possible to serialise/export a Property graph as RDF without data loss. Now, properties of relationships can be represented as RDF* triples as described in the previous section. Let’s look at an example using the movie database that you can load into neo4j by running :play movies .
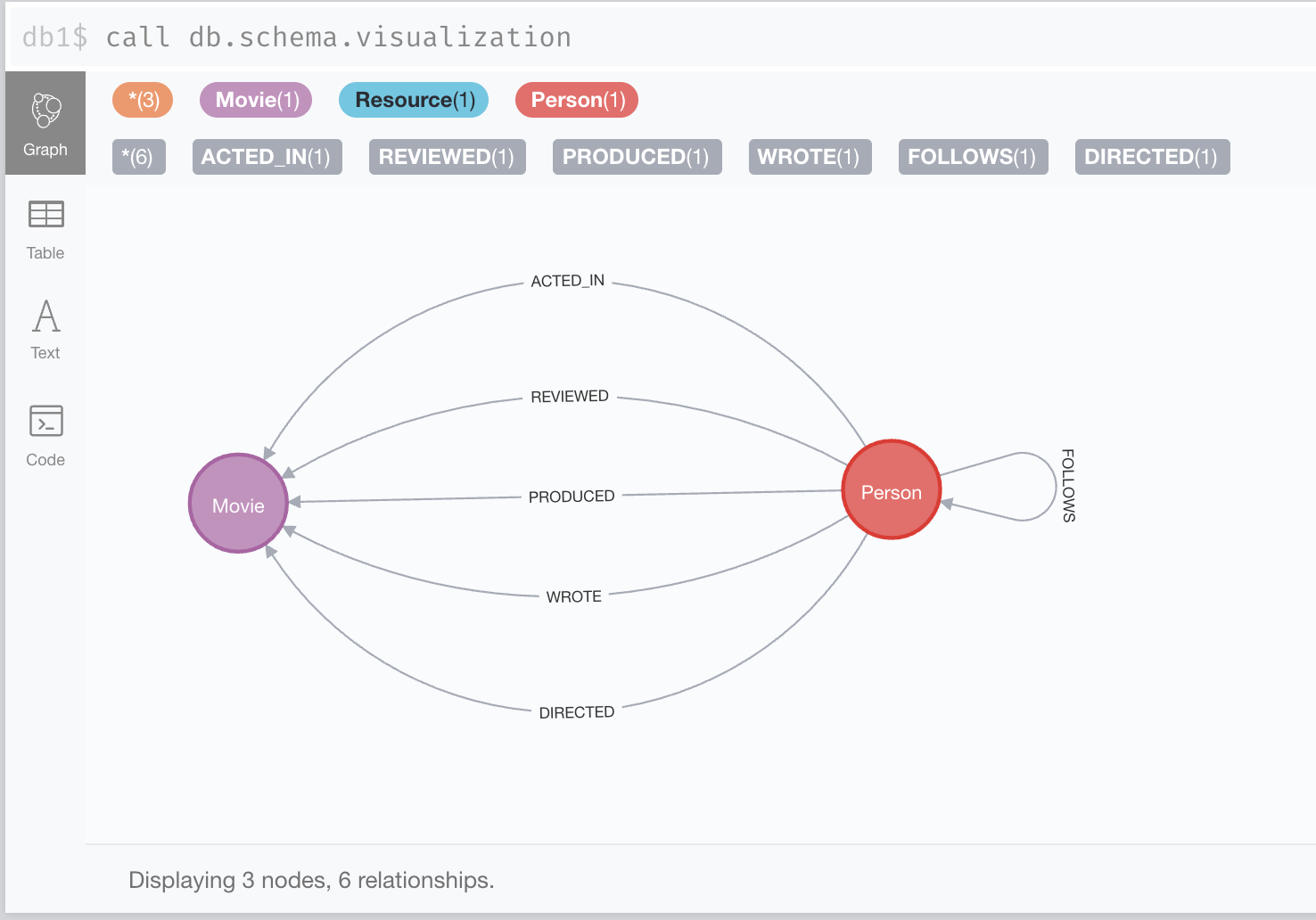
The schema for this simple graph is quite straightforward, it includes two types of entities: Person and Movie and a number of relationships between them as presented in the capture below. You can get a visual representation of the schema by running CALL db.schema.visualization()
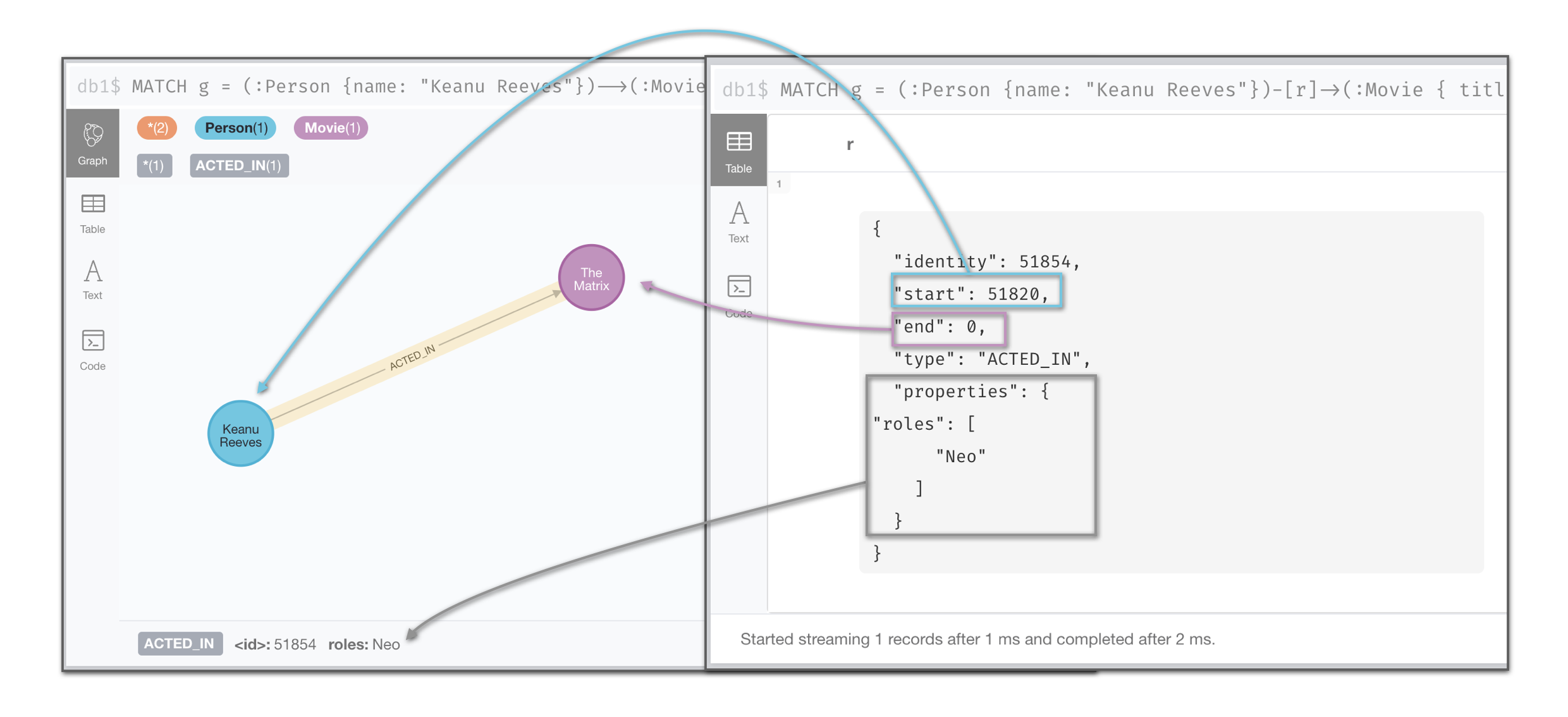
The relationship of interest is the one named ACTED_IN, connecting a Person to a Movie. It’s interesting because it encapsulates the role (or roles) that the person plays in that particular movie. We can look at an example by getting the details of Keanu Reeves’ involvement in the movie The Matrix
MATCH g = (:Person {name: "Keanu Reeves"})-->(:Movie { title: "The Matrix"})
RETURN gThe left image is the visual representation of Keanu Reeves’ connection to the movie and the right one is the machine readable view of the same connection. In this second one we see that a relationship is described by its unique identifier, its type, two pointers to the start and end nodes and a list of properties. In this case the only property is the role the actor plays in the movie.
If we wanted to serialise this information as RDF all we need to do is pass the previous query to the rdf/cypher endpoint (see manual) of our Neo4j database. Let’s test it in the browser:
:POST /rdf/db1/cypher
{"cypher": "MATCH g = (:Person {name: 'Keanu Reeves'})-->(:Movie { title: 'The Matrix'}) RETURN g", "format" : "Turtle*"}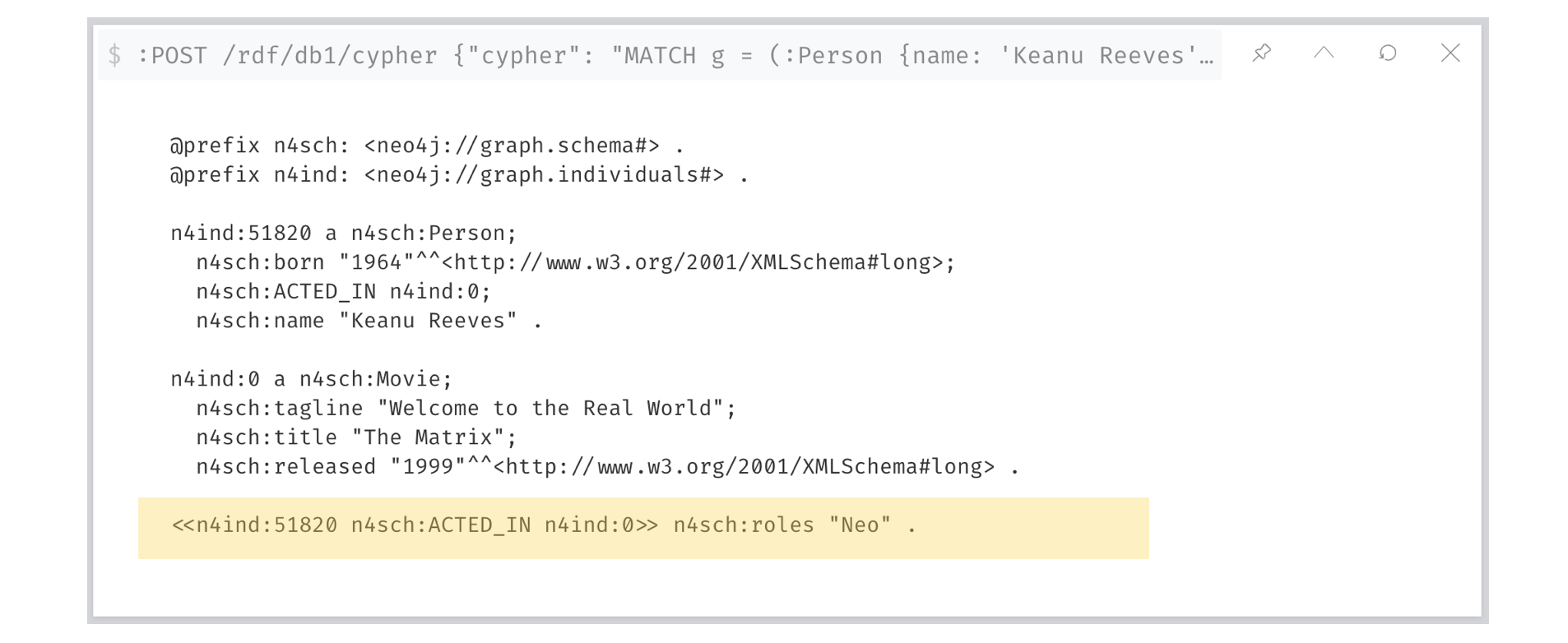
To show how straightforward it is to serialise multivalued properties, we can produce a complete export of every relationship Actor-[:ACTED_IN]->Movie where the actor played more than one role. This is the cypher query:
:POST /rdf/db1/cypher
{"cypher": "MATCH (:Person)-[ai:ACTED_IN]->() WHERE size(ai.roles) > 1 RETURN ai", "format" : "Turtle*"}Which produces the following Turtle* serialisation:
@prefix n4sch: <neo4j://graph.schema#> .
@prefix n4ind: <neo4j://graph.individuals#> .
<<n4ind:51853 n4sch:ACTED_IN n4ind:15>> n4sch:roles "DeDe", "Patricia Graynamore", "Angelica Graynamore" .
n4ind:51853 n4sch:ACTED_IN n4ind:15 .
n4ind:8 n4sch:ACTED_IN n4ind:42, n4ind:98 .
<<n4ind:8 n4sch:ACTED_IN n4ind:42>> n4sch:roles "Dermot Hoggins", "Dr. Henry Goose", "Zachry", "Isaac Sachs" .
<<n4ind:51823 n4sch:ACTED_IN n4ind:42>> n4sch:roles "Nurse Noakes", "Haskell Moore", "Bill Smoke", "Old Georgie", "Tadeusz Kesselring", "Boardman Mephi" .
n4ind:51823 n4sch:ACTED_IN n4ind:42 .
n4ind:44 n4sch:ACTED_IN n4ind:42 .
<<n4ind:44 n4sch:ACTED_IN n4ind:42>> n4sch:roles "Vyvyan Ayrs", "Captain Molyneux", "Timothy Cavendish" .
<<n4ind:43 n4sch:ACTED_IN n4ind:42>> n4sch:roles "Jocasta Ayrs", "Ovid", "Luisa Rey", "Meronym" .
n4ind:43 n4sch:ACTED_IN n4ind:42 .
<<n4ind:8 n4sch:ACTED_IN n4ind:98>> n4sch:roles "Conductor", "Hero Boy", "Father", "Santa Claus", "Scrooge", "Hobo" .Import: Building a Property Graph in Neo4j from RDF* data
Symmetric to the previous case, RDF* can also be used to import rich datasets into Neo4j to build a Property Graph. Let’s have a look at a couple of examples.
Previewing the Property Graph
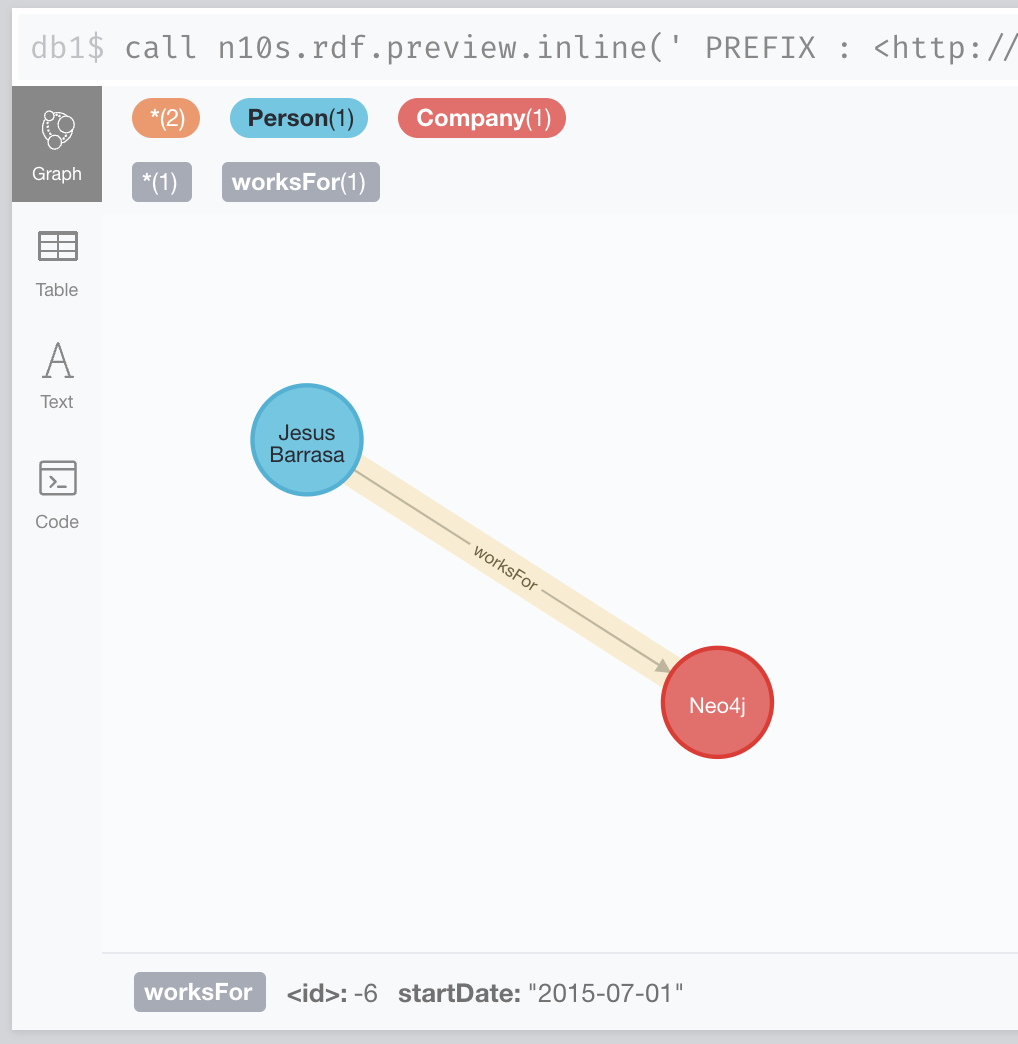
Before we persist any data in the graph, we can preview what an RDF* dataset would look like as a Porperty Graph. This is done with the n10s.rdf.preview procedures. Like all of the procedures in n10s we have two flavours: inline and fetch. The first one takes an RDF snippet passed as parameter and the second one takes a reference (url) where the RDF is supposed to be retrieved from. Here is an example of the inline mode in action with this short RDF* fragment about my current job:
call n10s.rdf.preview.inline('
PREFIX : <http://example/>
:jb a :Person ;
rdfs:label "Jesus Barrasa".
:neo4j a :Company ;
rdfs:label "Neo4j" .
<<:jb :worksFor :neo4j>> :startDate "2015-07-01"^^xsd:date .
',"Turtle*")Producing a visualisation like this one:
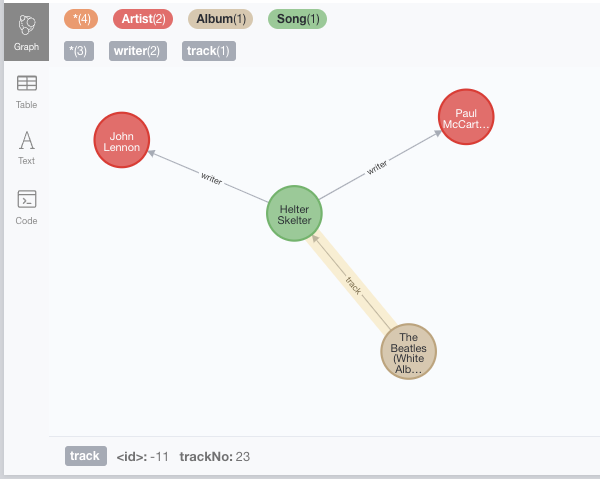
If instead we need to retrieve the RDF* from a URL (a SPARQL* service?), we will need to use the fetch form of the rdf.preview method. For this example we will use this simple RDF* document with some facts about The Beatles’ song Helter Skelter:

call n10s.rdf.preview.fetch('https://raw.githubusercontent.com/jbarrasa/datasets/master/rdfstar/beatles-hs.ttl',"Turtle*")Producing the following preview, where all relationships include the relevant properties: track number in the link between the album and the song and the contribution in the links between John and Paul and the song.
Importing the Property Graph
Not much to say about this one. All you need to do is take any of the previous ones and replace preview with import in the procedure name and the magic will happen! The graph will be persisted in Neo4j and you’ll get as result a summary of the execution.
call n10s.rdf.import.fetch('https://raw.githubusercontent.com/jbarrasa/datasets/master/rdfstar/beatles-hs.ttl',"Turtle*")
What’s interesting about this QuickGraph?
Well, it’s a simple one but I guess it gives you the possibility to create an RDF* endpoint in just a few clicks which is a pretty cool thing given that there are still not many out there.
Watch the video, give it a go and share your feedback. All details about installing n10s and getting started are in the user guide.
See you in the next post or at the neo4j community site.

Thanks for putting this together Jesus. I’ve tried following the guide on my local installation (neo4j v4.3.6 / n10s v4.3.0.1). Trying to import format “Turtle*” using the example above results in the error “Unrecognized serialization format: Turtle*”. What am I missing please?
LikeLike
You should use “Turtle-star” instead.
More details here: https://community.neo4j.com/t/not-able-to-load-turle-with-n10s-4-3-0-0/42686/2
LikeLike
Hi, thanks for your great work!
Quoted triples are defined recursively according to the current draft:
https://w3c.github.io/rdf-star/cg-spec/editors_draft.html
as in the following Turtle-star triples:
<< <> n4sch:role “Albert Goldman”>> :accordingTo :employee11 .
While successfully importing simpler rdf-star, I failed at importing such data using
CALL n10s.rdf.import.fetch(“file:///data/test_syntax.ttl”, “Turtle-star”);
on Neo4j 4.4.4 with neosemantics 4.4.0.0.
My question: Is or will it be possible to import and represent such data in Neo4j?
LikeLike
Hi Dirk, thanks for your comment. These kind of technical questions are more adequate for the community site (https://community.neo4j.com/) or the issues section of the GitHub repo (https://github.com/neo4j-labs/neosemantics/issues/). It’s easier to respond there and share code, etc.
But on this topic, maybe you want to have a look at this issue where we explore how to extend the default behavior of n10s.rdf.import.* for RDF-star
(https://github.com/neo4j-labs/neosemantics/issues/231)
Cheers,
JB
LikeLike
Thank you for the explanation. Quick question, can Neo4J Data Science “Node2Vec” Algorithm also be applied to a RDF Graph (imported using Neosemantics)? Thanks in advance for your reply.
LikeLike
Hi Claudia. Yes, absolutely.
You can use all features in the Graph Data Science module on any data in the Neo4j graph and that includes of course the data imported using neosemantics.
Good luck!
JB.
LikeLike