The dataset
For this example, I am going to use a sample movie dataset from the Cayley project. It’s a set of half a million triples about actors, directors and movies that can be downloaded here.
Here is what the dataset looks like:
</en/meet_the_parents> <name> "Meet the Parents" . </en/meet_the_parents> <type> </film/film> . </en/meet_the_parents> </film/film/directed_by> </en/jay_roach> . </en/meet_the_parents> </film/film/starring> _:28754 . _:28754 </film/performance/actor> </en/ben_stiller> . _:28754 </film/performance/character> "Gaylord Focker" . </en/meet_the_parents> </film/film/starring> _:28755 . ...
One could argue whether this dataset is actual RDF or just a triple based graph since it does not use valid URIs or even the RDF vocabulary (note for example that instead of http://www.w3.org/1999/02/22-rdf-syntax-ns#type we find just type). But this would be a rather pointless discussion in my opinion. For what it’s worth, the graph is parseable with standard RDF parsers which is enough and as we’ll see the problems derived from this can be fixed, which is the point of this post.
Loading the data into Neo4j
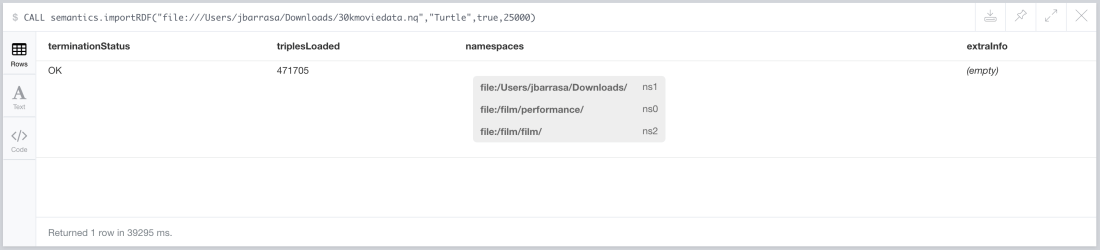
I’ll use the RDF Importer described here for the data load. Now, there is something to take into account, even though the data set is called ‘30kmoviedata.nq’ it does not contain quads but triples, so I tried the parser setting the serialization format to ‘N-Triples’. The parser threw an error complaining about the structure of the URIs:
Not a valid (absolute) IRI: /film/performance/actor [line 1]
However, funnily enough the file parses as Turtle format. So if you want to give it a try, remember to set the second parameter of the importRDF stored procedure to ‘Turtle’ and run the import in the usual way. It took only 39 seconds to load the 471K triples on my laptop.
Fixing the model
Fixing dense nodes representing categories
First thing we notice is that because the data set does not use the RDF vocabulary, the a <type> b statements are not transformed into labeled nodes as would have happened if rdf:type was used instead. So there are a couple of unusually dense nodes representing the categories (person and movie) because most of the nodes in the dataset are either actors or movies and are therefore linked to either one or the other category node. The two dense nodes are immediately visible in a small sample of 1000 nodes:

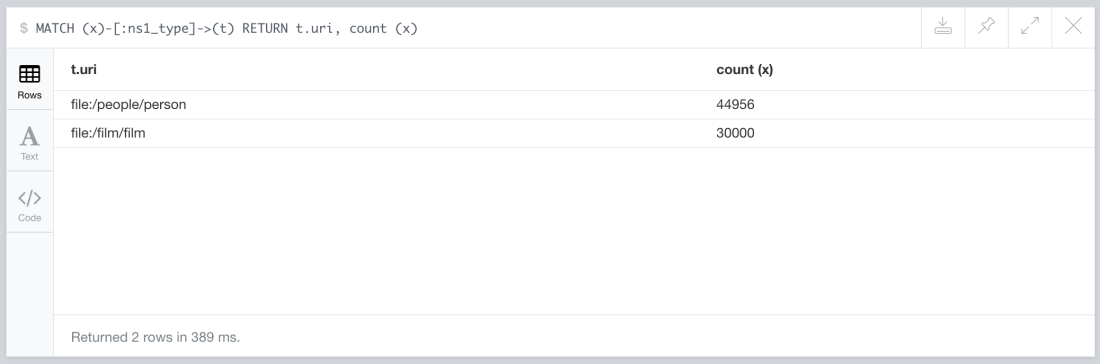
We can get counts on the number of nodes connected to each of them by running this query:
MATCH (x)-[:ns1_type]->(t) RETURN t.uri, count (x)
The natural way of representing categories in the Label Property Graph model is by using labels so let’s fix this! Here is the Cypher fragment that does the job:
MATCH (x)-[:ns1_type]->({uri : 'file:/film/film'})
SET x:Film
And once we have the nodes labeled with their categories we can get rid of the dense nodes and the links that connect the rest of the nodes to them.
MATCH (f {uri : 'file:/film/film'}) DETACH DELETE f
Exactly the same applies to the other category: ‘file:/film/person’
MATCH (x)-[:ns1_type]->({uri : 'file:/people/person'})
SET x:Person
MATCH (p {uri : 'file:/people/person'}) DETACH DELETE p
Fixing unneeded intermediate nodes holding relationship properties
In the tiny fragment that I copied at the beginning of the post, we can already see that the data set suffers from one of the known limitations of triple based graph models which is the impossibility of adding attributes to relationships. To do that, intermediate nodes need to be created. Let’s have a look at the example in the previous data fragment graphically.
Ben Stiller plays the role of Gaylord Focker in the movie Meet the Parents and when modelling this (think how would you draw that in a whiteboard) our intuition says something like this:
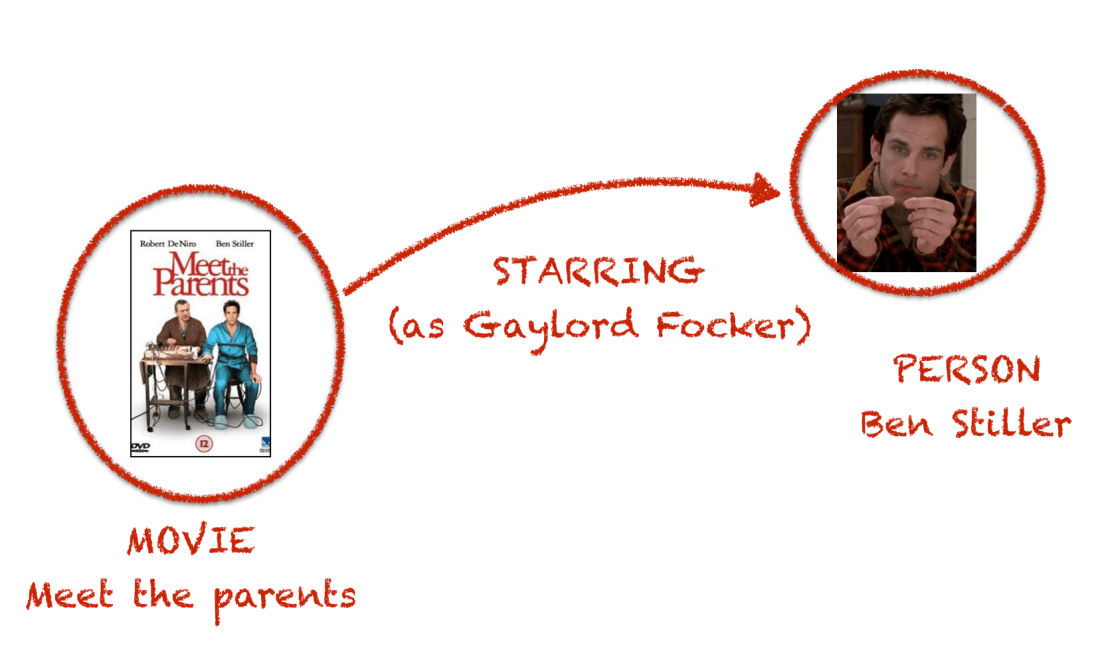
But in a triple based model you will need to introduce an intermediate node to hold the role played by an actor in a movie. Something like this.
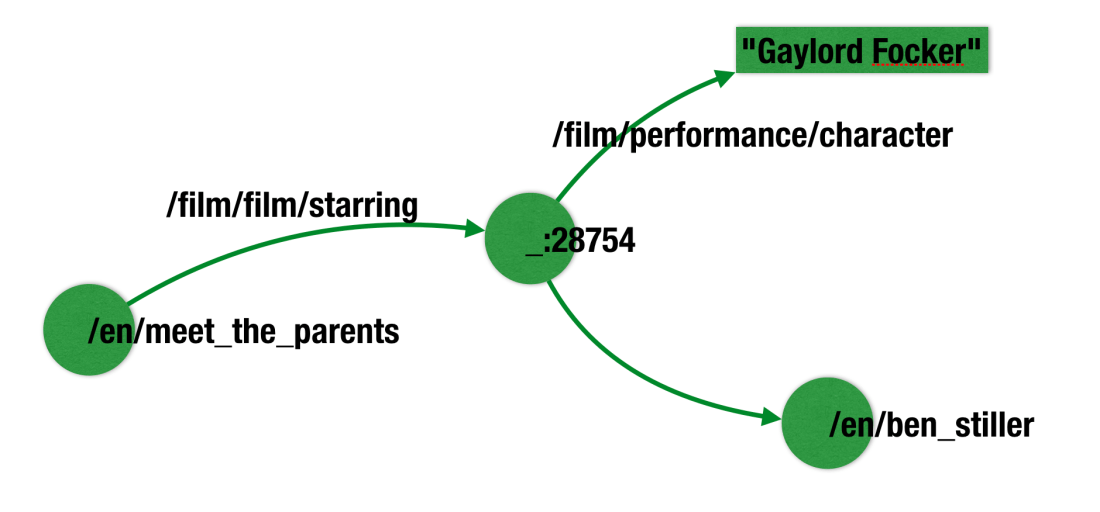
This obviously creates a gap between what you conceive when modelling a domain and what is stored in disk and ultimately queried. You will have to map what’s in your head, what you drew in the whiteboard when sketching the model to what the triple based formalism forces you to actually create. Does this ring a bell? Join tables in the relational model maybe? In your head it’s a many-to-many relationship but in the relational model it has to be modelled in a separate join table, an artificial construct imposed by the modelling paradigm that inevitably builds a gap between the conceptual model and the physical one. This ultimately makes your model harder to understand and maintain and your SQL queries looooooonger and less performant. But not to worry, we’ll fix this by using the property graph model, the one that is closer to the way we as humans understand and model domains.
But before we do that, let’s look at another problem derived from this. This complex model introduces the possibility of data quality problems in the form of broken links. What if we have the first leg connecting our intermediate node with the movie but no connection with the actor? It would be a totally meaningless piece of information. The pattern I’m describing would be expressed like this:
()-[r:ns2_starring]->(x) WHERE NOT (x)-[:ns0_actor]->()
And a query producing a ‘Data Quality’ report on this particular issue could look something like this:
MATCH ()-[r:ns2_starring]->(x) WHERE NOT (x)-[:ns0_actor]->() WITH COUNT(r) as brokenLinks MATCH ()-[r:ns2_starring]->(x)-[:ns0_actor]->() WITH COUNT(r) as linked, brokenLinks RETURN linked + brokenLinks as total, linked, brokenLinks, toFloat(brokenLinks)* 100/(linked + brokenLinks) as percentageBroken
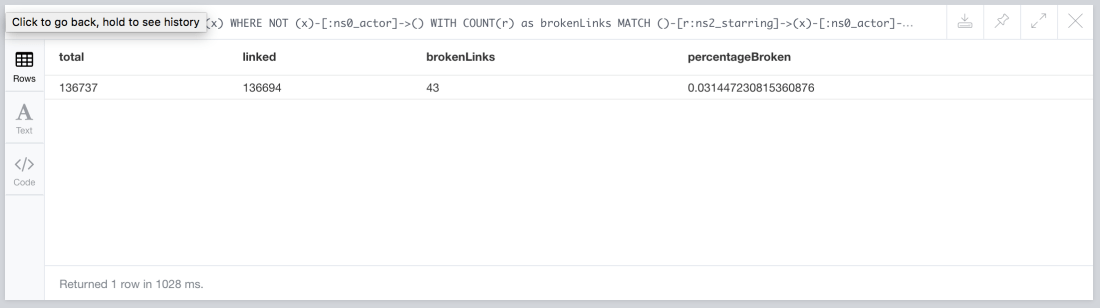
So 0.03% does not seem to be significant, probably the dataset was truncated in a bad way, which would explain the missing bits. Anyway, we can get rid of these broken links that don’t add any value to our graph. Here’s how:
MATCH ()-[r:ns2_starring]->(x) WHERE NOT (x)-[:ns0_actor]->() DETACH DELETE x
Ok, so now we are in a position to get rid of the ugly and unintuitive intermediate nodes that I described before and replace them with relationships containing attributes on them.
MATCH (film)-[r:ns2_starring]->(x)-[:ns0_actor]->(actor)
CREATE (actor)-[:ACTS_IN { character: x.ns0_character}]->(film)
DETACH DELETE x
...
Deleted 136694 nodes, set 15043 properties, created 136694 relationships, statement executed in 7029 ms.
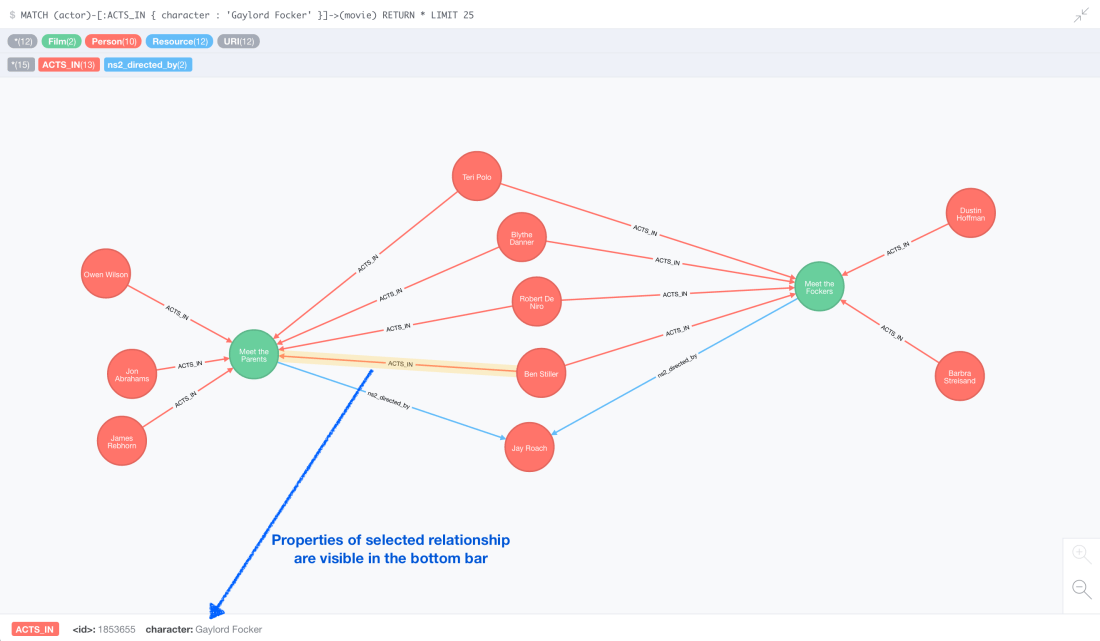
And voilà! Here is the final model zooming on the ‘Gaylord Focker’ area:
MATCH (actor)-[:ACTS_IN { character : 'Gaylord Focker' }]->(movie)
RETURN * LIMIT 25
And to finish, one of our favourites at Neo4j, a recommendation engine for Hollywood actors. Who should Ben Stiller work with? We’ll base this in the concept of friend-of-a-friend. If Ben has worked several times with actor X and actor X has worked several times with actor Y then there is a good chance that Ben might be interested in working with actor Y.
Here is the Cypher query that returns our best recommendations for Ben Stiller:
MATCH (ben:Person {ns1_name: 'Ben Stiller'})-[:ACTS_IN]->(movie)<-[:ACTS_IN]-(friend)
WITH ben, friend, count(movie) AS timesWorkedWithBen ORDER BY timesWorkedWithBen DESC LIMIT 3 //limit to top 3
MATCH (friend)-[:ACTS_IN]->(movie)<-[:ACTS_IN]-(friendOfFriend)
WHERE NOT (ben)-[:ACTS_IN]->(movie)<-[:ACTS_IN]-(friendOfFriend) AND friendOfFriend <> ben
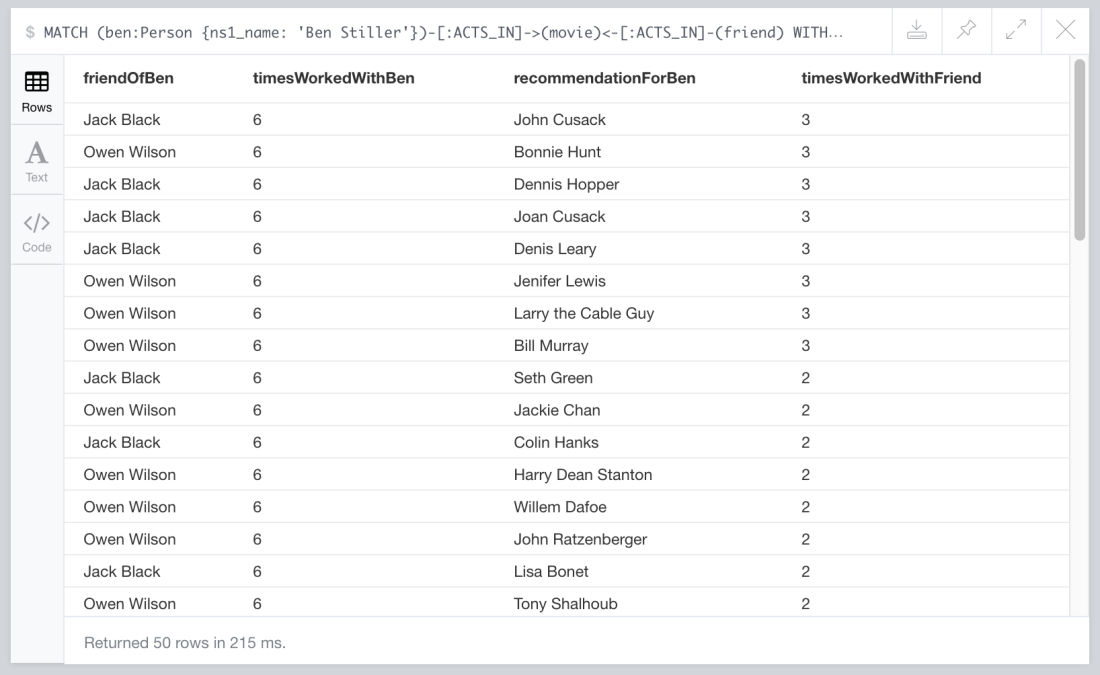
RETURN friend.ns1_name AS friendOfBen, timesWorkedWithBen, friendOfFriend.ns1_name AS recommendationForBen, count(movie) AS timesWorkedWithFriend ORDER BY timesWorkedWithFriend DESC limit 50
Easy, right? And here are the recommendations:
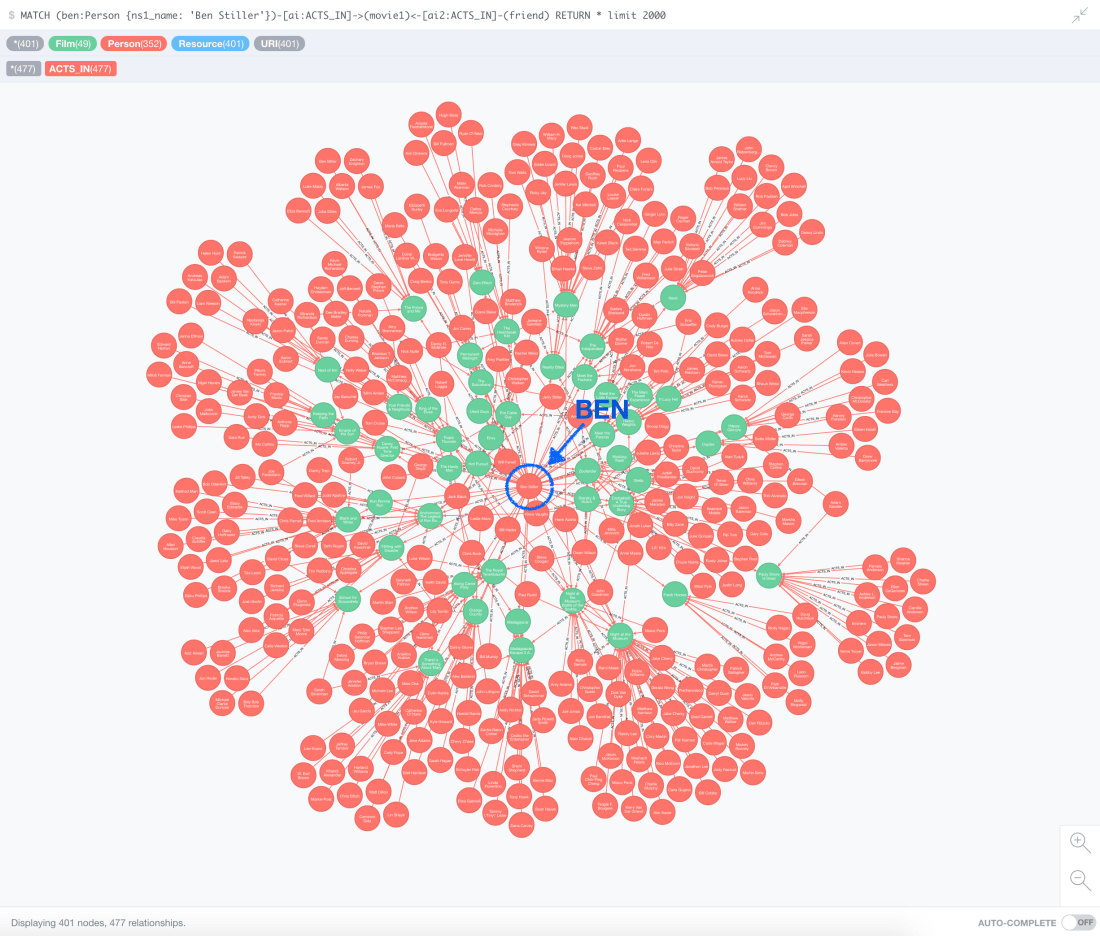
The following two visualisations give an idea of the portion of the graph explored with our recommendation query. This first one shows Ben’s friends and the movies where they worked together (~400 nodes in total):
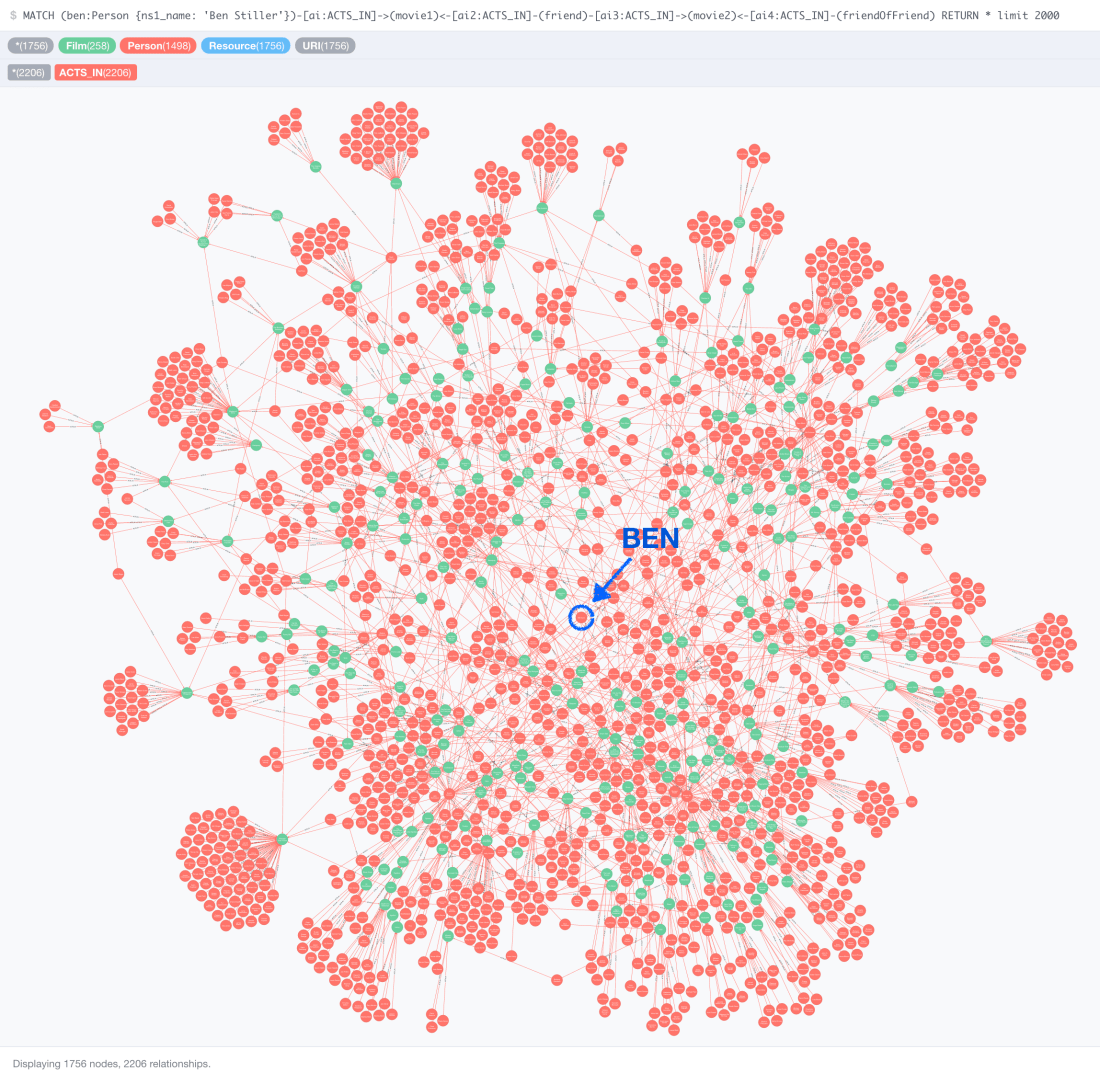
And the next shows Ben’s friends’ friends, again with the movies that connect them (~1800 nodes):
You can try to write something similar on the original triple based graph using SPARQL, Gremlin or any other language but I bet you it will be less compact, less intuitive and certainly less performant than the Cypher I wrote. Prove me wrong if you can 😉
What’s interesting about this QuickGraph?
The example highlights some of the modelling limitations of triple based graph models like RDF and how it is possible to transform a model originally created as RDF into a more intuitive and easier to query and explore using the Labeled Property Graph in Neo4j.

Great Article! Thanks
LikeLike