The dataset
For this QuickGraph I’ll use data about Wikipedia Categories. You may have noticed at the bottom of every Wikipedia article a section listing the categories it’s classified under. Every Wikipedia article will have at least one category, and categories branch into subcategories forming overlapping trees. It is sometimes possible for a category (and the Wikipedia hierarchy is an example of this) to be a subcategory of more than one parent category, so the hierarchy is effectively a graph.
I guess an example will be helpful at this point: If you open the Wikipedia page on the mathematician Leonard Euler you will find at the bottom of it the following list of categories:

If you click on any of them, for instance ‘Swiss mathematicians‘ you will be able to navigate up and down the hierarchy of categories from the selected one. I’ll go a couple of steps ahead here and show the final product before explaining how to build it: The structure you are navigating is a graph and looks something like this:
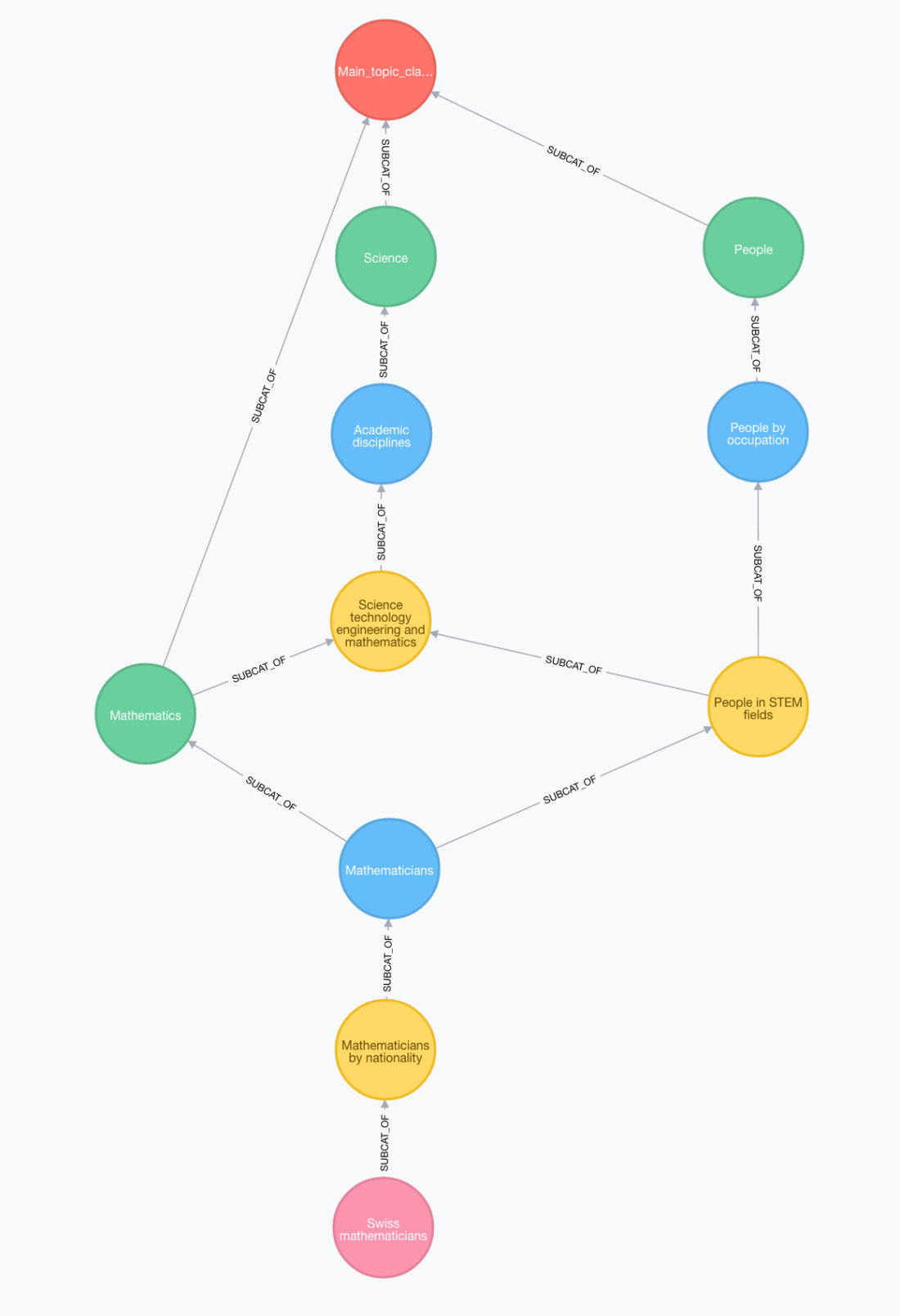
In the diagram the color coding of the Category nodes indicates the (shortest) distance to the root category so we will have Level1 (green) to Level4 (pink) categories. We can see that the ‘Swiss Mathematician’ category can be reached following many different paths from the root. A couple of examples would be:
People > People by occupation> People in STEM fields > Mathematicians > Mathematicians by nationality > Swiss mathematicians
or
Science > Academic disciplines> STEM > Mathematics > Mathematicians > Mathematicians by nationality > Swiss mathematicians
So this is the graph that we are going to build and explore/query in Neo4j in this blog post.
The data source
Wikipedia data can be accessed through the MediaWiki action API, and the specific request that returns information for a given category is described here and looks as follows:
https://en.wikipedia.org/w/api.php?format=json&action=query&list=categorymembers&cmtype=subcat&cmtitle=Category:Fundamental_categories&cmprop=ids|title&cmlimit=500
The request returns a simple JSON structure containing all subcategories of the one passed as parameter (cmtitle). Here is an example of the web service output:

Loading the data into Neo4j
Since the Wikipedia categorymembers web service takes the name of a category as input parameter, we’ll have to seed the graph with a root node in order to start loading categories. This node will be the starting point for our data load. For this example we will use the category “Main Topic Classification” which groupsWikipedia’s major topic classifications.
CREATE (c:Category:RootCategory {catId: '0000000', catName: 'Main_topic_classifications', fetched : false})
An index on category Ids will help speeding up the merges, so let’s add it.
CREATE INDEX ON :Category(catId)
Now from the top level category we’ll iteratively call the categorymembers web service and process the JSON fragment returned to create nodes and relationships in the graph. We will do this in Neo4j using the apoc.load.json procedure in the APOC library. Here is the Cypher script that does the job. It first invokes the web service with the name of the category, and then process the JSON that the web service returns by creating new instances of Category nodes connected to the parent trhough :SUBCAT_OF relationships.
MATCH (c:Category { fetched: false})
call apoc.load.json('https://en.wikipedia.org/w/api.php?format=json&action=query&list=categorymembers&cmtype=subcat&cmtitle=Category:' + replace(c.catName,' ', '%20') + '&cmprop=ids|title&cmlimit=500')
YIELD value as results
UNWIND results.query.categorymembers AS subcat
MERGE (sc:Category:Level1Category {catId: subcat.pageid})
ON CREATE SET sc.catName = substring(subcat.title,9),
sc.fetched = false
MERGE (sc)-[:SUBCAT_OF]->(c)
WITH DISTINCT c
SET c.fetched = true
Each iteration of the loader adds a new level to the category hierarchy by picking up all ‘unexpanded’ nodes and fetching for each of them all the subcategories. Nodes are marked on creation with the fetched : false property and once they have been expanded (subcategories retrieved and added to the graph) the property fetched is set to true.
So a first iteration of the loader after creating the top level category ” instantiates 13 new categories

Which are obviously the 13 main topic classifications in Wikipedia.


The second iteration of the loader picks each one of these 13 and instantiates its subcategories producing 423 new next level nodes.

A third iteration brings in 5815 new nodes and a fourth one takes the final number close to 50K categories by adding 42840 more. It’s important to keep in mind that every category expansion involves a request being sent to the wikipedia API so I would not recommend this approach for hierarchies more than 4 levels deep. If you’re interested in loading the whole set of categories probably the best would be to download them as an RDB dump (the files enwiki-latest-category.sql.gz and enwiki-latest-categorylinks.sql.gz from the downloads page) and then use the superfast batch importer to create your graph in Neo4j. Maybe an idea for a future graphgist?
Ok, we have now a graph of 50K odd categories from Wikipedia organised hierarchically via :SUBCAT_OF relationships, so let’s try and run some interesting queries on them. Here’s how a few thousand categories (up to level three) look like in the Neo4j browser: the root node is the red one towards the center of the image, Level 1 categories are the green ones, followed by Level 2 in blue and Level 3 in yellow.
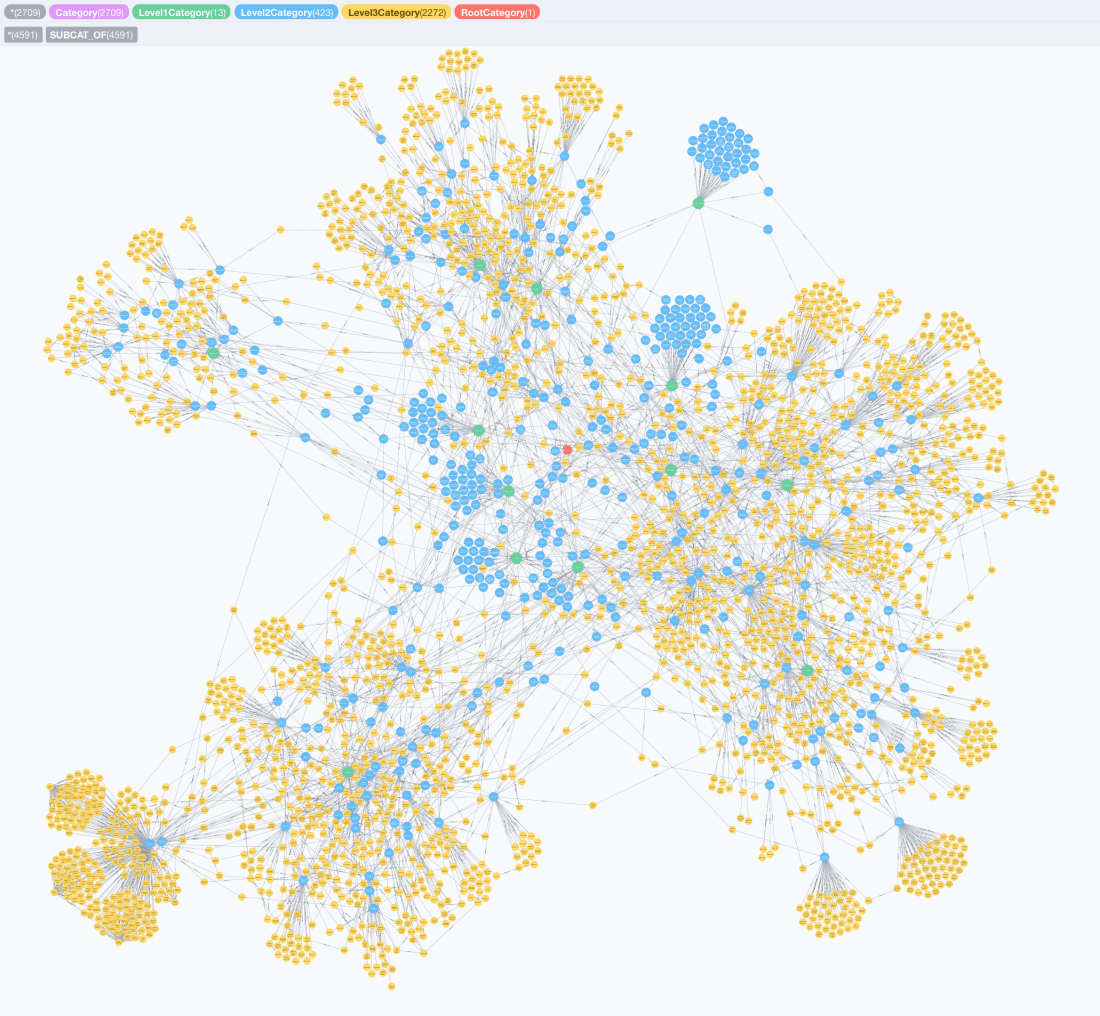
An alternative graph based on a smaller number of initial thematic classifications can be built using “Fundamental_categories” as root. In Wikipedia’s terms, this alternative classification “is intended to contain all and only the few most fundamental ontological categories which can reasonably be expected to contain every possible Wikipedia article under their category trees”. I leave this for the interested reader to try.
Querying the graph
What is the shortest full hierarchy for a given category?
Let’s use for this example the ‘Swiss Mathematicians’ example from the introduction.
MATCH shortestFullHierarchy = shortestPath((swissMatem:Category {catName : 'Swiss mathematicians'})-[:SUBCAT_OF*]->(root:RootCategory))
RETURN shortestFullHierarchy
The shortestPath function returns the expected depth four hierarchy:

There will be cases where more than one shortest path exist, and these can be picked up with the allShortestPaths variant of the shortest path function:
MATCH shortestFullHierarchies = allShortestPaths((swissMatem:Category {catName : 'Philosophers by period'})-[:SUBCAT_OF*]->(root:RootCategory))
RETURN shortestFullHierarchies
The query returns all shortest full hierarchies (all with max depth of 4) for the ‘Ancient philosophers’ category.

What are the richest categories in the top four levels of the Wikipedia?
What is a rich category? Well, this is a QuickGraph so I’ll come up with my own quick (although I hope still minimally reasoned) definition but let’s keep in mind that I’m not trying to build a theory about hierarchy relevance but rather show how the graph can be easily queried in interesting ways.
Right, so a rich category is one that has loads of subcategories because that means it’s complex enough to be broken down with such a high level of detail. Similarly, a rich category is also one that can be categorised from different perspectives, or in other words, one that has multiple parent categories. But we will want to discard unbalanced ones (many subcategories but very few super-categories or vice versa) to avoid enumeration-style categories like “Religion by country”, “Culture by nationality” or “People by ethnic or national descent”. With these three criteria we can build a graph query that returns our top ten. Here is the Cypher for our richest categories:
MATCH (cat:Category) WITH cat, size((cat)-[:SUBCAT_OF]->()) as superCatDegree, size(()-[:SUBCAT_OF]->(cat)) as subCatDegree WHERE ABS(toFloat(superCatDegree - subCatDegree)/(superCatDegree + subCatDegree)) < 0.4 RETURN cat.catName, (superCatDegree + subCatDegree)/2 AS richness ORDER BY richness DESC LIMIT 10
And the results are quite interesting…

If now we want to explore visually the Marxism category…
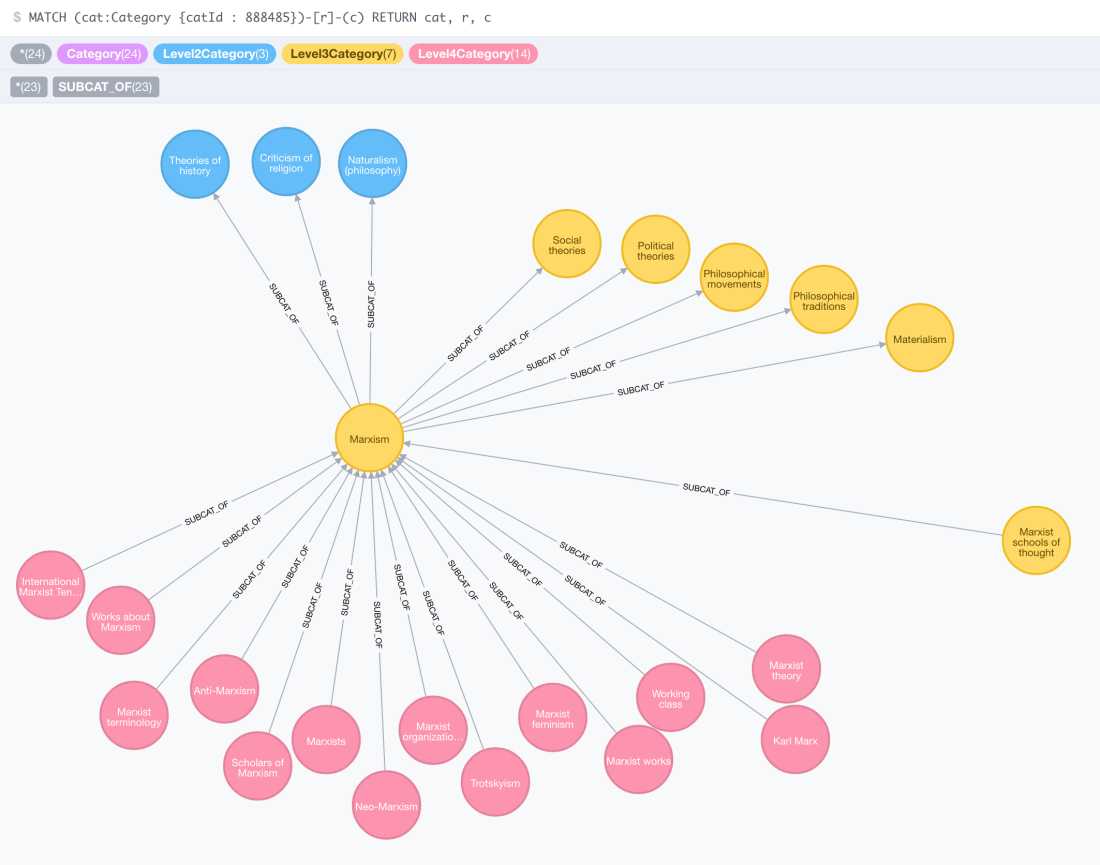
Unexpectedly long hierarchies!
One thing that caught my eye from the point of view of the structure of the graph was the fact that even though I had only loaded 4 levels, I was able to find way longer chains of parent-child categories. This is because not all :SUBCAT_OF relationships go from level n to level n-1. That is actually what makes the structure a graph and not a tree. The following query returns :SUBCAT_OF chains longer than 12 ( path =()-[r:SUBCAT_OF*12..]->() ), but checks that every node in the chain is at a maximum distance of 4 from the root ( shortestPath((node)-[:SUBCAT_OF*..4]->(root:Category {catId:’0000000′})) ).
MATCH path =()-[r:SUBCAT_OF*12..]->() WITH path LIMIT 1
UNWIND nodes(path) AS node
MATCH shortest = shortestPath((node)-[:SUBCAT_OF*..4]->(root:Category {catId:'0000000'}))
RETURN path, shortest
And the first result shows how effectively, even though there are chains of length 6 (and longer than that, actually) we can easily see that all the nodes in the chain are never more than 4 hops away from the root node. This is consistent with the fact that we’ve only loaded 4 levels of the category hierarchy.
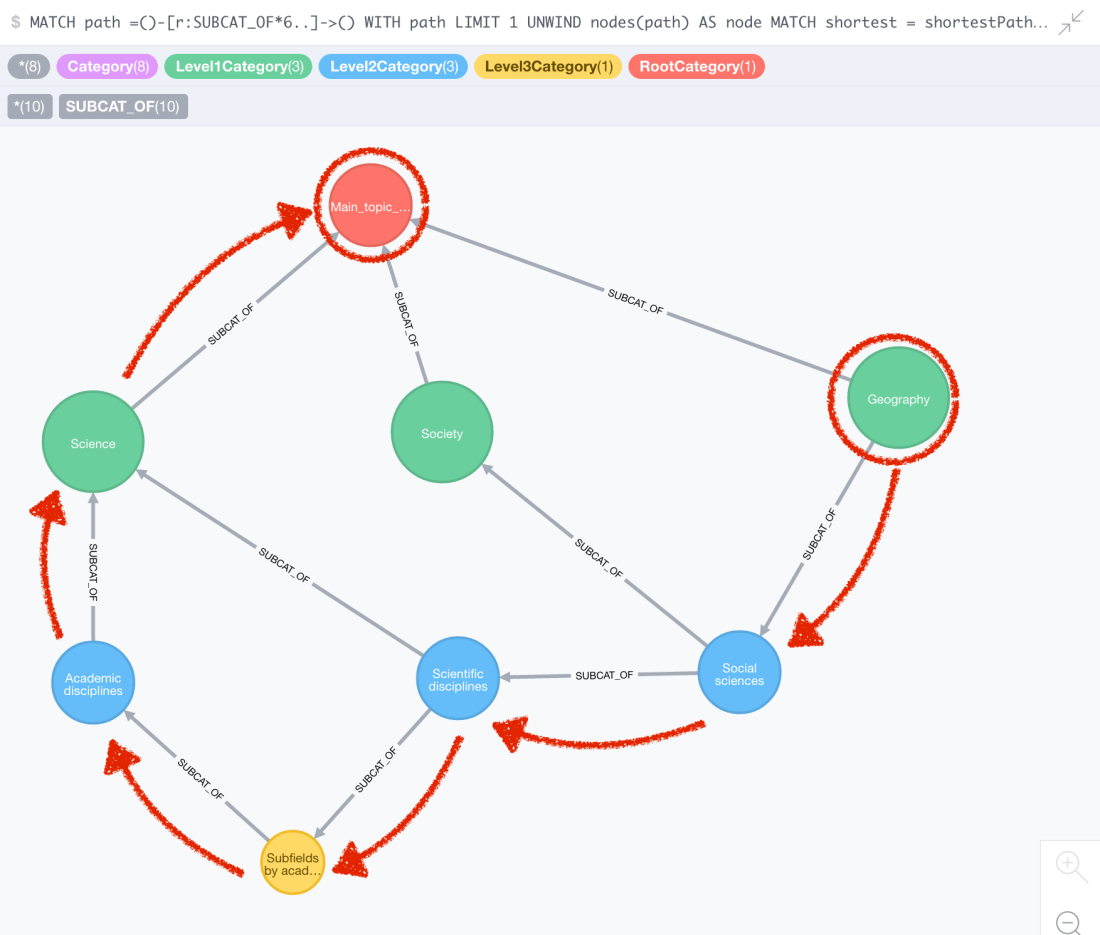
Loops!
Yes, there are some. So if one day you decide to read the whole Wikipedia (as you do) and you choose to do it by category, then be careful not to enter into an infinite loop of knowledge 🙂
Looops are easy to pick up with this simple Cypher query:
MATCH loop = (cat)-[r:SUBCAT_OF*]->(cat) RETURN loop LIMIT 1


The caption on the left shows a loop and the one on the right shows the same loop but keeping the hierarchical order. Green nodes are level 1 categories, blue ones are level 2 and finally yellow ones represent the level 3 categories. The interesting thing is that Geography, even though it’s level one, it’s also a subcategory of Earth Sciences that is level 3. The same thing happens with Nature, being both level 1 and a subcategory of Environmental social science concepts, which is level 3. These two extra relationships create the loop that produces the following chain of :SUBCAT_OF.
MATCH loop = (cat)-[r:SUBCAT_OF*]->(cat) RETURN reduce(s = "", x IN nodes(loop) | s + ' > '+ x.catName) AS categoryChain limit 1

You can also try to find longer loops by just specifying the minimum length of the path
loop = (cat)-[r:SUBCAT_OF*12..]->(cat)
And get chains like:

What’s interesting about this QuickGraph?
The graph is built directly from querying a web service from the MediaWiki action API. The apoc.load.json procedure in the APOC library can invoke this service and ingest the JSON structure returned all within your Cypher script. Find how to install and use (and extend!) the APOC library of stored procedures for Neo4j.
Rich category hierarchies are graphs and extremely useful tool for scenarios like recommendation systems or graph-enhanced search.

2 thoughts on “QuickGraph#2 How is Wikipedia’s knowledge organised”