The dataset
For this example I am going to use my browser history data. Most browsers store this data in SQLite. This means relational data, easy to access from Neo4j using the apoc.load.jdbc stored procedure.
I’m a Chrome user, and in my Mac, Chrome stores the history db at
~/Library/Application Support/Google/Chrome/Default/History
There are two main tables in the History DB: urls and visits. I’m going to explore them directly from Neo4j’s browser using the same apoc.load.jdbc procedure. In order to do that, you’ll have to download first a jdbc driver for SQLite, and copy it in the plugins directory of your Neo4j instance. Also keep in mind that Chrome locks the History DB when the browser is open so if you want to play with it(even read only acces) you will have to either close the browser or as I did, copy the DB (a single file) somewhere else and work from that snapshot.
This Cypher fragment will return the first few records of the urls table and we see on them things like an unique identifier for the page, its url, title of the page and some counters with the number of visits and the number of times the url has been typed as opposed to reached by following a hyperlink.
CALL apoc.load.jdbc("jdbc:sqlite:/Users/jbarrasa/Documents/Data/History",
"urls") yield row
WITH row LIMIT 10
RETURN *
The results look like this on my browser history.

The visits table contain information about the page visit event, a timestamp (visit_time), a unique identifier (id) for each visit and most interesting, whether the visit follows a previous one (from_visit). This would mean that there was a click on a hyperlink that lead from page A to page B.
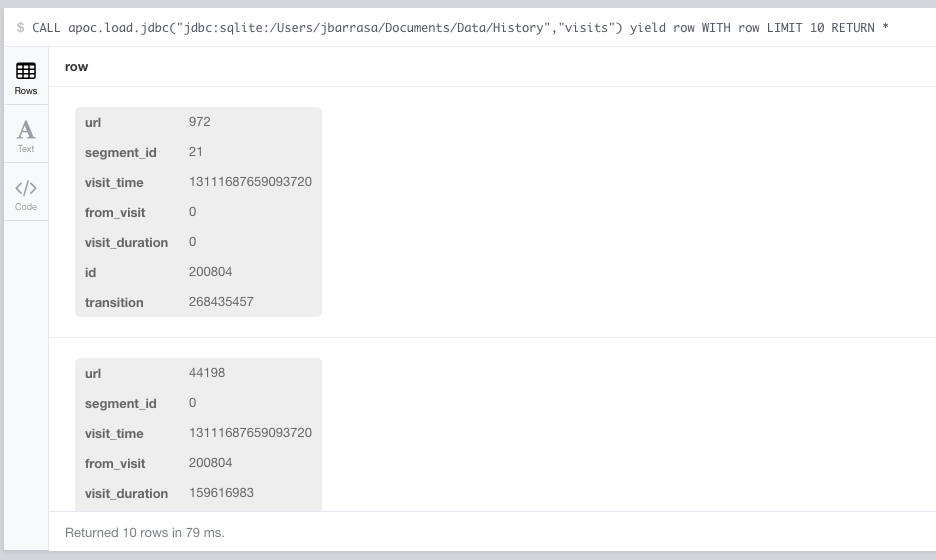
A bit of SQL manipulation using the date and time functions on the SQLite side will filter out the columns from the visits table that we don’t care about for this experiment and also format the timestamp in a user friendly date and time.
SELECT id, url, time(((visit_time/1000000)-11644473600), 'unixepoch') as visit_time, date(((visit_time/1000000)-11644473600), 'unixepoch') as visit_date, visit_time as visit_time_raw FROM visits
Here’s what records look like using this query. Nice and ready to be imported into Neo4j.

Loading the data into Neo4j
The model I’m planning to build is quite simple: I’ll use a node to represent a web page and a separate one to represent each individual visit to a page. Each visit event is linked to the page through the :VISIT_TO_PAGE relationship, and chained page visits (hyperlink navigation) are linked through the :NAVIGATION_TO relationship. Here is what that looks visually on an example navigation from a post on the Neo4j blog to a page with some code on Github:

Ok, so let’s go with the import scripts. First the creation of Page nodes out of every record in the urls table:
CALL apoc.load.jdbc("jdbc:sqlite:/Users/jbarrasa/Documents/Data/History",
"urls") yield row
WITH row
CREATE (p:Page {page_id: row.id,
page_url: row.url,
page_title: row.title,
page_visit_count: row.visit_count,
page_typed_count: row.typed_count})
And I’ll do the same with the visits, but linking them to the pages we’ve just loaded. Actually, to accelerate the page lookup I’ll create an index on page ids first.
CREATE INDEX ON :Page(page_id)
And here’s the Cypher running the visit data load.
WITH "SELECT id, url, visit_time as visit_time_raw,
time(((visit_time/1000000)-11644473600), 'unixepoch') as visit_time,
date(((visit_time/1000000)-11644473600), 'unixepoch') as visit_date
FROM visits" AS sqlstring
CALL apoc.load.jdbc("jdbc:sqlite:/Users/jbarrasa/Documents/Data/History",
sqlstring ) yield row
WITH row
MATCH (p:Page {page_id: row.url})
CREATE (v:PageVisit { visit_id: row.id,
visit_time: row.visit_time,
visit_date: row.visit_date,
visit_timestamp: row.visit_time_raw})
CREATE (v)-[:VISIT_TO_PAGE]->(p)
And finally, I’ll load the transitions between visits but as we did before with the pages, let’s create first an index on visit ids:
CREATE INDEX ON :PageVisit(visit_id)
WITH "SELECT id, from_visit, transition, segment_id, visit_duration
FROM visits" AS sqlstring
CALL apoc.load.jdbc("jdbc:sqlite:/Users/jbarrasa/Documents/Data/History",
sqlstring
) yield row
WITH row
MATCH (v1:PageVisit {visit_id: row.from_visit}),
(v2:PageVisit {visit_id: row.id})
CREATE (v1)-[:NAVIGATION_TO]->(v2)
So we are ready to start querying our graph!
Querying the graph
Let’s look for a direct navigation in the graph that goes for instance from a page in the Neo4j web site to Twitter.
MATCH (v1)-[:VISIT_TO_PAGE]->(p1),
(v2)-[:VISIT_TO_PAGE]->(p2),
(v1)-[:NAVIGATION_TO]->(v2)
WHERE p1.page_url CONTAINS 'neo4j.com'
AND p2.page_url CONTAINS 'twitter.com'
RETURN * LIMIT 10
In my browser history data, this produces the following output. Notice that I’ve extended it to include an extra navigation step. I’ve done that just by clicking on the graph visualisation in the Neo4j browser to make the example more understandable:
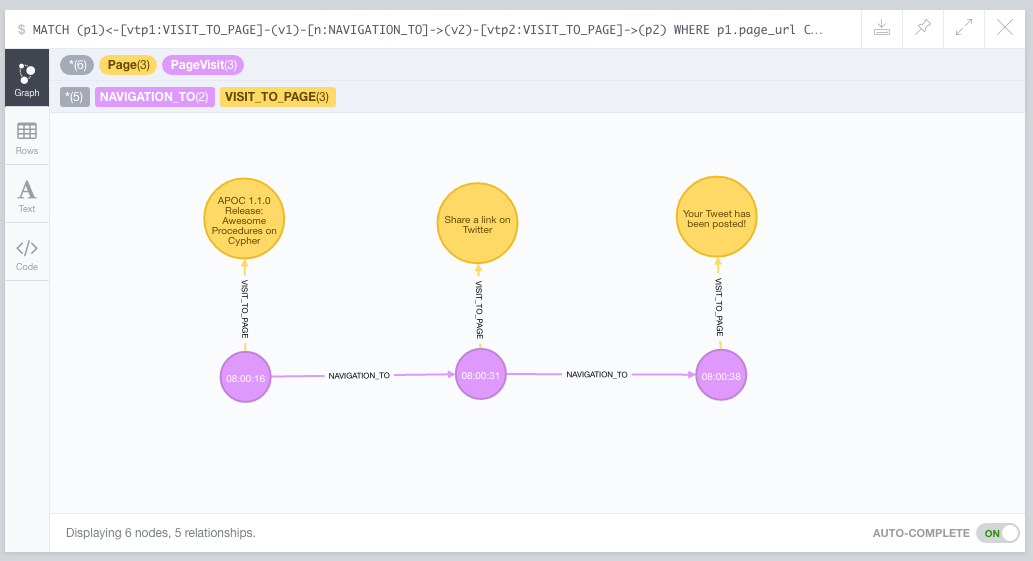
It actually corresponds to a visit to the Neo4j blog, followed by me tweeting how cool was what I just read. The proof that I’m working with real data is the actual tweet (!)
Ok, so while this basic model is good to analyse individual journeys, I think extracting a Site node by aggregating all pages in the same site can give us interesting insights. Let’s go for it.
Extending the model
This could be done in different ways, for example we could write a stored procedure and call it from a Cypher script. Having the full power of java, we could do a proper parsing of the url string to extract the domain.
I will do it differently though, I’ll run a SQL query on the History SQLite DB including string transformations to substring the urls and extract the domain name (sort of). The SQL that extracts the root of the url could be the following one:
SELECT id, substr(url,9,instr(substr(url,9),'/')-1) as site_root FROM urls WHERE instr(url, 'https://')=1 UNION SELECT id, substr(url,8,instr(substr(url,8),'/')-1) as site_root FROM urls WHERE instr(url, 'http://')=1
Quite horrible, I know. But my intention is to show how the graph can be extended with new data without having to recreate it. Quite a common scenario when you work with graphs, but relax, graphs are good at accommodating change, nothing to do with RDBMS migrations when having to change your schema.
So this new query produces rows containing just the domain (the root of the url) and the page id that I will use to match to previously loaded pages. Something like this:

And the Cypher that loads it and adds the extra information in our graph would be this:
WITH "select substr(url,9,instr(substr(url,9),'/')-1) as site_root, id
from urls where instr(url, 'https://')=1
UNION
select substr(url,8,instr(substr(url,8),'/')-1) as site_root, id
from urls where instr(url, 'http://')=1" AS query
CALL apoc.load.jdbc("jdbc:sqlite:/Users/jbarrasa/Documents/Data/History",
query) yield row
WITH row
MATCH (p:Page {page_id: row.id})
MERGE (s:Site {site_root: row.site_root})
CREATE (p)-[:PAGE_IN_SITE]->(s)
And once we have the sites we can include weighted site level navigation. The weight is simply calculated by summing the number of transitions between pages belonging to each site. Here is the Cypher that does the job:
MATCH (s:Site)<-[:PAGE_IN_SITE]-()<-[:VISIT_TO_PAGE]-()<-[inbound:NAVIGATION_TO]-()-[:VISIT_TO_PAGE]->()-[:PAGE_IN_SITE]->(otherSite)
WHERE otherSite <> s
WITH otherSite, s, count(inbound) as weight
CREATE (otherSite)-[sn:SITE_DIRECT_NAVIGATION{weight:weight}]->(s)
This is a much richer graph, where we can traverse not only individual journeys, but also Site level connections. In the following visualisation we can see that there are some transitions between the http://www.theguardian.co.uk and the http://www.bbc.co.uk sites (indicated in green), also to other sites like en.wikipedia.org. In the same capture we can see one of the individual navigations that explain the existence of a :SITE_DIRECT_NAVIGATION relationship between the Guardian node and the BBC one. It actually represents a hyperlink I clicked on the Guardian’s article that connected it to a BBC one. The purple sequence of events (page visits) details my journey and the yellow nodes represent the pages, pretty much the same we saw on the previous example from neo4j.com to twitter.com.
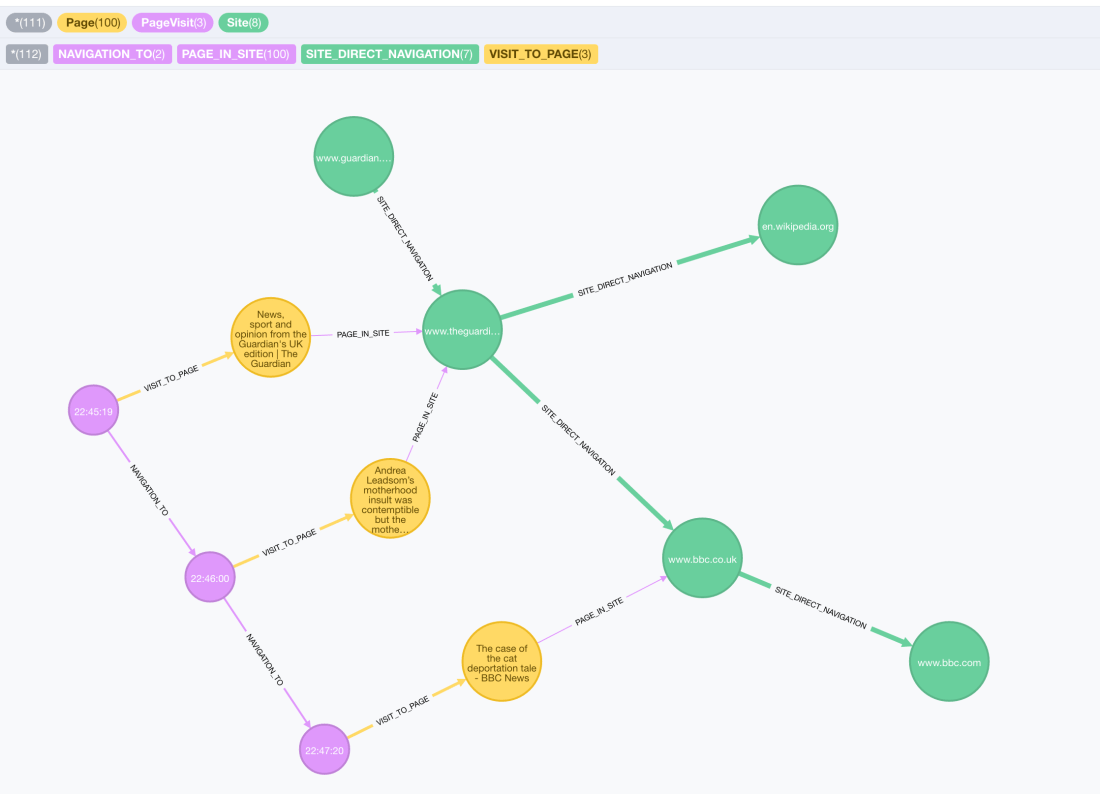
We can also have a bird’s eye view of a few thousand of the nodes on the graph and notice some interesting facts:

I’ve highlighted some interesting Site nodes. We can se that the most highly connected (more central in the visualization) are the googles and the URL shortening services (t.co, bit.ly, etc.). It makes sense because you typically navigate in and out of them, they are kind of bridge nodes in your navigation. This is confirmed if we run the betweenness centrality algorithm on the sites and their connections. Briefly, betweenness centrality is an indicator of a node’s centrality in a graph and is equal to the number of shortest paths from all nodes to all others that pass through that node.
Here is the Cypher script, again invoking the graph algo implementation as a stored procedure that you can find in the amazing APOC library:
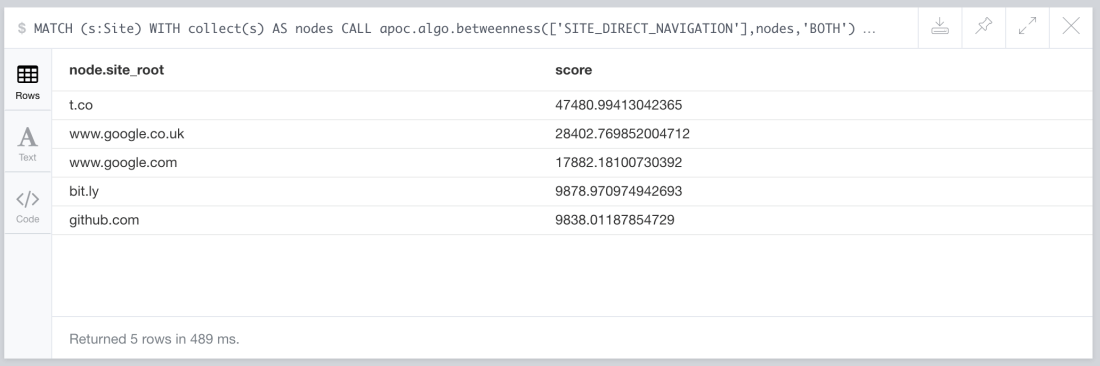
MATCH (s:Site) WITH collect(s) AS nodes CALL apoc.algo.betweenness(['SITE_DIRECT_NAVIGATION'],nodes,'BOTH') YIELD node, score RETURN node.site_root, score ORDER BY score DESC LIMIT 5
And these are the top five results of the computation on my browser history.
I’m sure you can think of many other interesting queries on your own navigation, what’s the average length of a journey, how many different sites it traverses, is it mostly intra-site? Are there any isolated clusters? An example of this in my browser history are the Amazon sites (amazon.co.uk and music.amazon.co.uk). There seem to be loads of transitions (navigation) between them but none in or out to/from other sites. You can visually see this on the bottom left part of the previous bird’s eye view. I’m sure you will come up with many more but I’ll finish this QuickGraph with a query involving some serious path exploration.
The question is: Which sites have I navigated to from LinkedIn pages, how many times have I reached them and how long (as in how many hyperlink clicks) did it take me to get to them? You may be asking yourself how on earth would you even express that in SQL(?!?!). Well, not to worry, you’ll be pleased to see that it takes less writing expressing the query in Cypher than it takes to do it in English. Here it is:
MATCH (v1)-[:VISIT_TO_PAGE]->(p1)-[:PAGE_IN_SITE]-(s1:Site {site_root: "www.linkedin.com"})
MATCH p = (v1)-[:NAVIGATION_TO*]->(v2)-[:VISIT_TO_PAGE]->(p2)-[:PAGE_IN_SITE]-(s2)
WHERE s2 <> s1
WITH length(p) AS pathlen, s2.site_root AS site
RETURN AVG(pathlen) AS avglen, count(*) AS count, site ORDER BY avglen
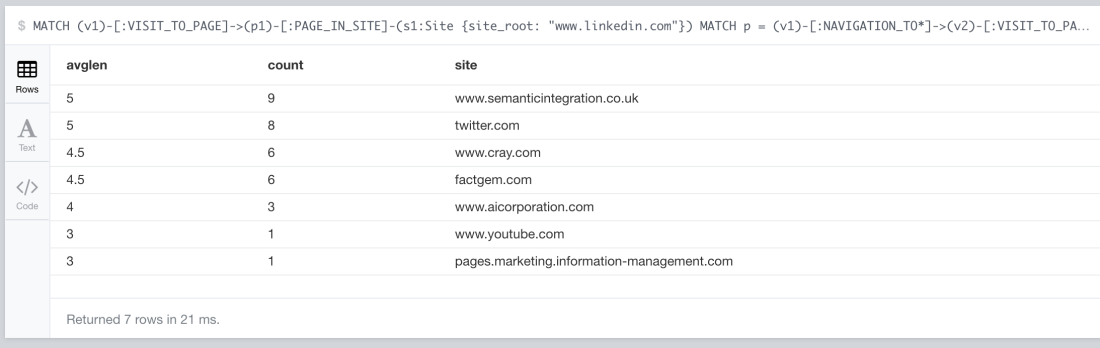
And my results, 21 milliseconds later…
What’s interesting about this QuickGraph?
This experiment shows several interesting things, the first being how straightforward it can be to load relational data into Neo4j using the apoc.load.jdbc stored procedure. As a matter of fact, the same applies to other types of data sources for example Web Services as I described in previous posts.
The second takeaway is how modelling and storing as a graph data that is naturally a graph (sequences of page visits) as opposed to shoehorning it into relational tables opens a lot of opportunities for querying and exploration that would be unthinkable in SQL.
Finally I’ve also shown how some graph algorithms (betweenness centrality) can be applied easily to your graph using stored procedures in Cypher. Worth mentioning that you can extend the list of available ones by writing your own and easily deploying it on your Neo4j instance.

Great writeup. However I’m unable to load the data.
“`Failed to invoke procedure `apoc.load.jdbc`: Caused by: java.lang.RuntimeException: Cannot execute SQL statement `SELECT * FROM urls`.
Error:
No suitable driver found for jdbc:sqlite:///Users/redacted/Documents/Neo4j/browser.history/History“`
I have the following (executable jars) in my plugins directory
-rwxr-xr-x@ apoc-3.0.4.1-all.jar
-rwxrwxrwx@ neo4j-jdbc-driver-3.0.jar
-rwxrwxrwx neo4j-spatial-0.20-neo4j-3.0.3-server-plugin.jar
-rwxrwxrwx@ sqlite-jdbc-3.14.2.1.jar
Any help greatly appreciated
LikeLike
Hi Riley, sorry for the late reply.
Have you registered the driver?
You’ll need to run this before running the actual query:
CALL apoc.load.driver(”)
Here is a pointer to the APOC user guide with some examples on that: https://neo4j-contrib.github.io/neo4j-apoc-procedures/#_load_jdbc
Cheers,
JB.
LikeLike