If you want to understand the differences and similarities between RDF and the Labeled Property Graph implemented by Neo4j, I’d recommend you watch this talk I gave at Graph Connect San Francisco in October 2016.
Intro
Let me start with some basics: RDF is a standard for data exchange, but it does not impose any particular way of storing data.
What do I mean by that? I mean that data can be persisted in many ways: tables, documents, key-value pairs, property graphs, triple graphs… and still be published/exchanged as RDF.
It is true though that the bigger the paradigm impedance mismatch -the difference between RDF’s modelling paradigm (a graph) and the underlying store’s one-, the more complicated and inefficient the translation for both ingestion and publishing will be.
I’ve been blogging over the last few months about how Neo4j can easily import RDF data and in this post I’ll focus on the opposite: How can a Neo4j graph be published/exposed as RDF.
Because in case you didn’t know, you can work with Neo4j getting the benefits of native graph storage and processing -best performance, data integrity and scalability- while being totally ‘open standards‘ to the eyes of any RDF aware application.
Oh! hang on… and your store will also be fully open source!
A “Turing style” test of RDFness
In this first section I’ll show the simplest way in which data from a graph in Neo4j can be published as RDF but I’ll also demonstrate that it is possible to import an RDF dataset into Neo without loss of information in a way that the RDF produced when querying Neo4j is identical to that produced by the original triple store.

You’ll probably be familiar with the Turing test where a human evaluator tests a machine’s ability to exhibit intelligent behaviour, to the point where it’s indistinguishable from that of a human. Well, my test aims to prove Neo4j’s ability to exhibit “RDF behaviour” to an RDF consuming application, making it indistinguishable from that of a triple store. To do this I’ll use the neosemantics neo4j extension.
The simplest test one can think of, could be something like this:
Starting from an RDF dataset living in a triple store, we migrate it (all or partially) into Neo4j. Now if we run a Given a SPARQL DESCRIBE <uri> query on the triple store and its equivalent rdf/describe/uri<uri> in Neo4j, do they return the same set of triples? If that is the case -and if we also want to be pompous- we could say that the results are semantically equivalent, and therefore indistinguishable to a consumer application.
We are going to run this test step by step on data from the British National Bibliography dataset:
Get an RDF node description from the triple store
To do that, we’ll run the following SPARQL DESCRIBE query in the British National Bibliography public SPARQL endpoint, or alternatively in the more user friendly SPARQL editor.
DESCRIBE <http://bnb.data.bl.uk/id/person/BulgakovMikhail1891-1940>
The request returns an RDF fragment containing all information about Mikhail Bulgakov in the BNB. A pretty cool author, by the way, which I strongly recommend. The fragment actually contains 86 triples, the first of which are these:
<http://bnb.data.bl.uk/id/person/BulgakovMikhail1891-1940> <http://xmlns.com/foaf/0.1/givenName> "Mikhail" . <http://bnb.data.bl.uk/id/person/BulgakovMikhail1891-1940> <http://www.w3.org/2000/01/rdf-schema#label> "Bulgakov, Mikhail, 1891-1940" . <http://bnb.data.bl.uk/id/person/BulgakovMikhail1891-1940> <http://xmlns.com/foaf/0.1/familyName> "Bulgakov" . <http://bnb.data.bl.uk/id/person/BulgakovMikhail1891-1940> <http://xmlns.com/foaf/0.1/name> "Mikhail Bulgakov" . <http://bnb.data.bl.uk/id/person/BulgakovMikhail1891-1940> <http://www.bl.uk/schemas/bibliographic/blterms#hasCreated> <http://bnb.data.bl.uk/id/resource/010535795> . <http://bnb.data.bl.uk/id/person/BulgakovMikhail1891-1940> <http://www.bl.uk/schemas/bibliographic/blterms#hasCreated> <http://bnb.data.bl.uk/id/resource/008720599> . ...
You can get the whole set running the query in the SPARQL editor I mentioned before or sending an HTTP request with the query to the SPARQL endpoint:
curl -i http://bnb.data.bl.uk/sparql?query=DESCRIBE+%3Chttp%3A%2F%2Fbnb.data.bl.uk%2Fid%2Fperson%2FBulgakovMikhail1891-1940%3E -H Accept:text/plain
Ok, so that’s our base line, exactly the output we want to get from Neo4j to be able to affirm that they are indistinguishable to an RDF consuming application.
Move the data from the triple store to Neo4j
We need to load the RDF data into Neo4j. We could load the whole British National Bibliography since it’s available for download as RDF, but for this example we are going to load just the portion of data that we need.
I will not go into the details of how this happens as it’s been described in previous blog posts and with some examples. The semantics.importRDF procedure runs a straightforward and lossless import of RDF data into Neo4j. The procedure is part of the neosemantics extension. If you want to run the test with me on your Neo4j instance, now is the moment when you need to install it (instructions in the README).
Once the extension ins installed, the migration could not be simpler, just run the following stored procedure:
CALL semantics.importRDF("http://bnb.data.bl.uk/sparql?query=DESCRIBE+%3Chttp%3A%2F%2Fbnb.data.bl.uk%2Fid%2Fperson%2FBulgakovMikhail1891-1940%3E",
"RDF/XML",true,true,500)
We are passing as parameter the url of the BNB SPARQL endpoint returning the RDF data needed for our test, along with some import configuration options. The output of the execution shows that the 86 triples have been correctly imported into Neo4j:

Now that the data is in Neo4j and you can query it with Cypher and visualise it in the browser. Here is a query example returning Bulgakov and all the nodes he’s connected to:
MATCH (a)-[b]-(c:Resource { uri: "http://bnb.data.bl.uk/id/person/BulgakovMikhail1891-1940"})
RETURN *
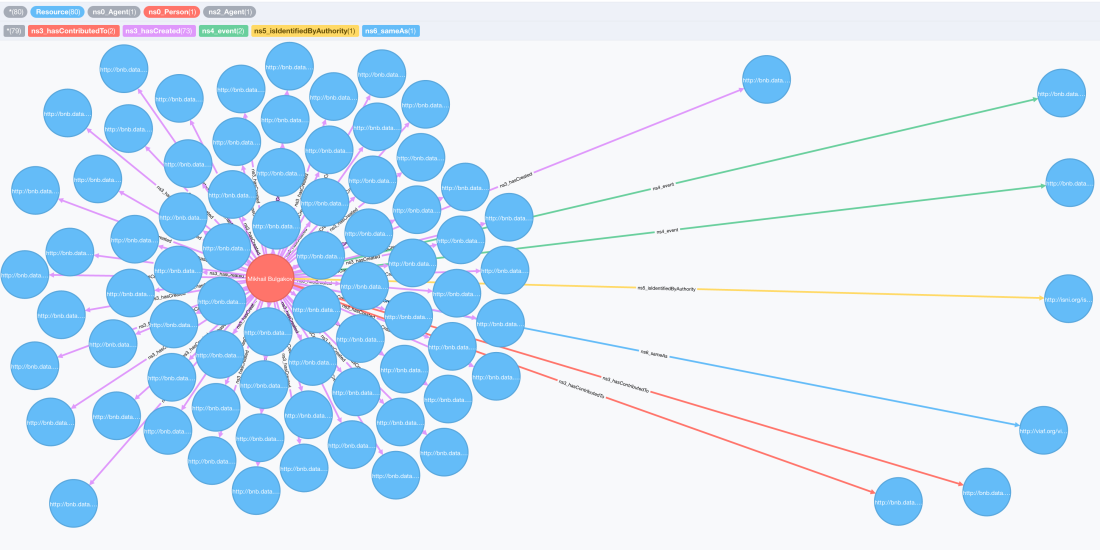
There is actually not much information in the graph yet, just the node representing good old Mikhail with a few properties (name, uri, etc…) and connections to the works he created or contributed to, the events of his birth and death and a couple more. But let’s not worry about size for now, well deal with that later. The question was: can we now query our Neo4j graph and produce the original set of RDF triples? Let’s see.
Get an RDF description of the same node, now from Neo4j
The neosemantics repo also includes an extensions (http endpoints) that provide precisely this capability. The equivalent in Neo4j of the SPARQL DESCRIBE on Mikhail Bulgakov would be the following:
:GET /rdf/describe/uri?nodeuri=http://bnb.data.bl.uk/id/person/BulgakovMikhail1891-1940
If you run it in the browser, you will get the default serialisation which is JSON-LD, something like this:
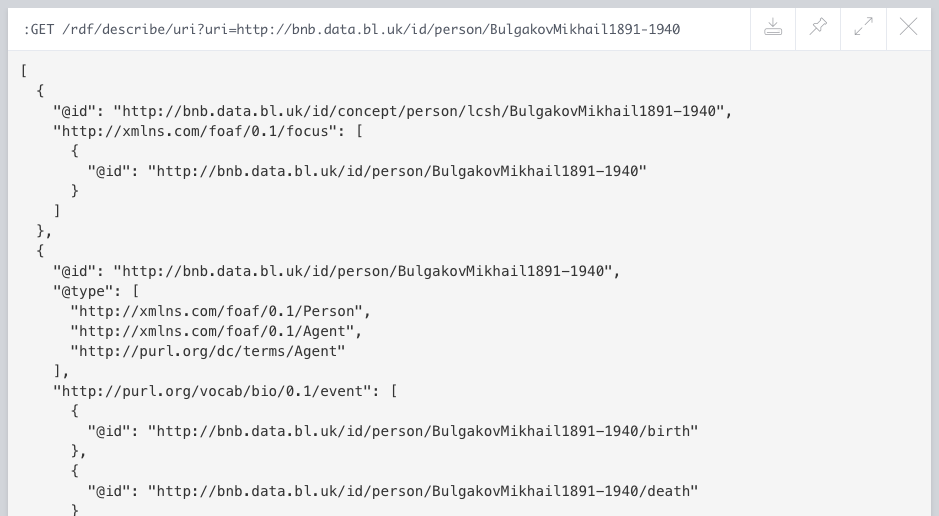
But if you set in the request header the serialisation format of your choice -for example using curl again- you can get the RDF fragment in any of the available formats.
curl -i http://localhost:7474/rdf/describe/uri?nodeuri=http://bnb.data.bl.uk/id/person/BulgakovMikhail1891-1940 -H accept:text/plain
Well, you should not be surprised to know that it return 86 triples, exactly the same set that the original query on the triple store returned.
So mission accomplished. At least for the basic case.
RDF out Neo4j’s movie database
I thought it could be interesting to prove that an RDF dataset can be imported into Neo4j and then published without loss of information but OK, most of you may not care much about existing RDF datasets, that’s fair enough. You have a graph in Neo4j and you just want to publish it as RDF. This means that in your graph, the nodes don’t necessarily have a property for the uri (why would they?) or are labelled as Resources. Not a problem.
Ok, so if your graph is not the result of some RDF import, the service you want to use instead of the uri based one, is the nodeid based equivalent.
:GET /rdf/describe/id?nodeid=<nodeid>
We’ll use for this example Neo4j’s movie database. You can get it loaded in your Neo4j instance by running
:play movies
You can get the ID of a node either directly by clicking on it on the browser or by running a simple query like this one:
MATCH (x:Movie {title: "Unforgiven"})
RETURN ID(x)
In my Neo4j instance, the returned ID is 97 so the GET request would pass this ID and return in the browser the JSON-LD serialisation of the node representing the movie “Unforgiven” with its attributes and the set of nodes connected to it (both inbound and outbound connections):

But as in the previous case, the endpoint can also produce your favourite serialisation just by setting it in the accept parameter in the request header.
curl -i http://localhost:7474/rdf/describe/id?nodeid=97 -H accept:text/plain
When setting the serialisation to N-Triples forma the previous request gets you these triples:
<neo4j://indiv#97> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <neo4j://vocabulary#Movie> . <neo4j://indiv#97> <neo4j://vocabulary#tagline> "It's a hell of a thing, killing a man" . <neo4j://indiv#97> <neo4j://vocabulary#title> "Unforgiven" . <neo4j://indiv#97> <neo4j://vocabulary#released> "1992"^^<http://www.w3.org/2001/XMLSchema#long> . <neo4j://indiv#167> <neo4j://vocabulary#REVIEWED> <neo4j://indiv#97> . <neo4j://indiv#89> <neo4j://vocabulary#ACTED_IN> <neo4j://indiv#97> . <neo4j://indiv#99> <neo4j://vocabulary#DIRECTED> <neo4j://indiv#97> . <neo4j://indiv#98> <neo4j://vocabulary#ACTED_IN> <neo4j://indiv#97> . <neo4j://indiv#99> <neo4j://vocabulary#ACTED_IN> <neo4j://indiv#97> .
The sharpest of you may notice when you run it that there is a bit missing. There are relationship properties in the movie database that are lost in the RDF fragment. Yes, that is because there is no way of expressing that in RDF. At least not without recurring to horribly complicated patterns like reification or singleton property that are effectively unusable in any practical real world use case. But we’ll get to that too in future posts.
Takeaways
I guess the main one is that if you want to get the benefits of native graph storage and be able to query your graph with Cypher in Neo4j but also want to:
- be able to easily import RDF data into your graph and/or
- offer an RDF “open standards compliant” API for publishing your graph
Well, that’s absolutely fine, because we’ve just seen how Neo4j does a great job at producing and consuming RDF.
Remember: RDF is about data exchange, not about storage.
There is more to come on producing RDF from Neo4j than what I’ve shown in this post. For instance, publishing the results of a Cypher query as RDF. Does it sound interesting?Watch this space.
Also I’d love to hear your feedback!

This is great work ! Was wondering if this could be proxied with RDF4J as a SPARQL endpoint? I think this approach in it’s current form it could be exported to a file and brought in to RDF4J and provide value immediately, but not sure if it would support ad-hoc SPARQL queries as-is. The ontop project has their own custom wars/jars for RDF4J , perhaps this work could be extended in this manner or help with ideas?
https://github.com/ontop/ontop/wiki/ObdalibSPARQLendpoint
LikeLike
Hi Omar. Yes, I guess it goes both ways. I was focusing on importing RDF data into Neo4j to be able to query it with Cypher and get the benefits of native graph storage. But you can also export a Property Graph from Neo4j into an RDF aware framework like RDF4J and query it with SPARQL. Why not?
In this second case though, it’s not guaranteed there will be no loss of information since as you know things like relationship properties cannot be easily expressed in RDF.
Cheers,
JB.
LikeLike
great work Jesus! I have an issue when importing my turtle files:
Neo.ClientError.Procedure.ProcedureCallFailed: Failed to invoke procedure `semantics.importRDF`: Caused by: org.neo4j.graphdb.MultipleFoundException: Found multiple nodes with label: ‘Resource’, property name: ‘uri’ and property value: ‘https://…1522761126’ while only one was expected.
how does it work if we add the same resource twice? shouldn’t it automatically merge them?
LikeLike
Hi Ali, sorry for the super late response.
These kind of issues are better managed in Github. Would you mind raising it as an issue there with context so I can try to reproduce and fix? Here’s the link: https://github.com/jbarrasa/neosemantics/issues
But answering your question, yes it should merge resources with the same URI.
Thanks!
JB.
LikeLike
Do I need neo4j enterprise for any of this? I am trying to import https://id.nlm.nih.gov/mesh/ which is stored in ftp://ftp.nlm.nih.gov/online/mesh/rdf/mesh.nt.gz. I am the maintainer of the software. I added the PREFIX statements/namespaces just as you described using:
CREATE (n:NamespacePrefixDefinition {
`http://www.w3.org/1999/02/22-rdf-syntax-ns#`: ‘rdf’,
`http://www.w3.org/2000/01/rdf-schema#`: ‘rdfs’,
`http://www.w3.org/2001/XMLSchema#`: ‘xsd’,
`http://www.w3.org/2002/07/owl#`: ‘owl’,
`http://id.nlm.nih.gov/mesh/vocab#`: ‘meshv’,
`http://id.nlm.nih.gov/mesh/`: ‘mesh’
}) RETURN n
However I’m not quite sure how to import the vocabulary, which is https://id.nlm.nih.gov/mesh/vocabulary.ttl
Of course I want to import it before I worry about entailment rules or anything like that.
Thanks,
-Dan
LikeLike
I see from your next comment that you managed to make it work in the end.
In any case, this kind of tech questions is better addressed in the GitHub repo instead of here in the blog.
I’d recommend in the future you raise any concern as an issue here: https://github.com/jbarrasa/neosemantics
Thanks for your interest!
LikeLike
Think I got it –
CALL semantics.liteOntoImport(‘https://id.nlm.nih.gov/mesh/vocabulary.ttl’, ‘Turtle’)
Now, onto the not-compressed N-Triples download. Yikes.
LikeLike
The problem I have with neo4j vs standard triple stores is neo4j limits the number of relationships, while triple stores can have lots. For example property graphs of neo4j you define the static relationships and it is fine, but with RDF, the relationship is usually just the word that connects the subject and predicate. So you can easily get more than 65k relationships. How do you deal with this issue
LikeLike
Hi Yondu, neo4j does not limit the number of relationships you can have. You can have billions of them if you wish. The limit is on the number of relationship types.
Now I would argue that if a model has more than 65k different types of relationships then maybe there is an issue but of a different type 🙂
My advice would be to look at remodeling for example taking advantage of properties in relationships, something that is possible in Property Graphs but not in RDF graphs.
I honestly don’t think this is an issue.
Are you in this situation?
LikeLike
Hello Jesús,
For the importRDF (v 3.5.0.3 of neosemantic extension) is it possible to give a header parameter like Authorization: Bearer ? I see in the last version it seems available.
CALL n10s.rdf.import.fetch(“https://bnb.data.bl.uk/sparql”,”Turtle”, {
handleVocabUris: “IGNORE”,
headerParams: { Accept: “application/turtle”},
payload: “query=” + apoc.text.urlencode(“DESCRIBE “)
});
Thanks for this great extension !
Raphaël
LikeLike
Hi Raphaël, yes it is.
Here’s a link to the section in the 3.5 manual where that’s described [https://neo4j.com/docs/labs/nsmntx/3.5/import/#advancedfetching].
Also for technical questions i’d recommend you post them in the neo4j community site. There is a specific section for RDF integrations [https://community.neo4j.com/c/integrations/linked-data-rdf-ontology].
I hope this helps.
JB.
LikeLike
Ok perfect, Thanks !
LikeLike